Roadmap to a Full Quant Tech Stack

I’ve wanted to write a blog post like this for quite some time now. As someone who just recently (re-)discovered his love for coding, getting into the universe of existing programs, frameworks, libraries and best practices can feel overwhelming at times.
However, after some weeks of experimenting with my setup, I feel confident enough to write this small excerpt about my current tech stack. I will update this overview article from time to time to include my latest insights / tools, so feel free to revisit anytime!
1. Wait, Full Quant Tech Stack?
So, what do I mean by Full Quant Tech Stack? Full stack refers to the full spectrum of a software system – from front to back, i.e. from a frontend such as a graphical interface / website, to the programming logic in between, all the way to the backend (database). Since I want my quant coding adventures to be as independent of any one-size-fits-all solution as possible, as well as learn how to develop a full application from scratch, I have scouted the internet and most well-known quant exchange websites to come up with a set of tools for my coding endeavours.
Building up a full tech stack for quantitative / algorithmic trading encompasses the following modules:
full-quant-tech-stack/ ├─ backend/ ├─ algo-engine/ ├─ trading-engine/ ├─ frontend/
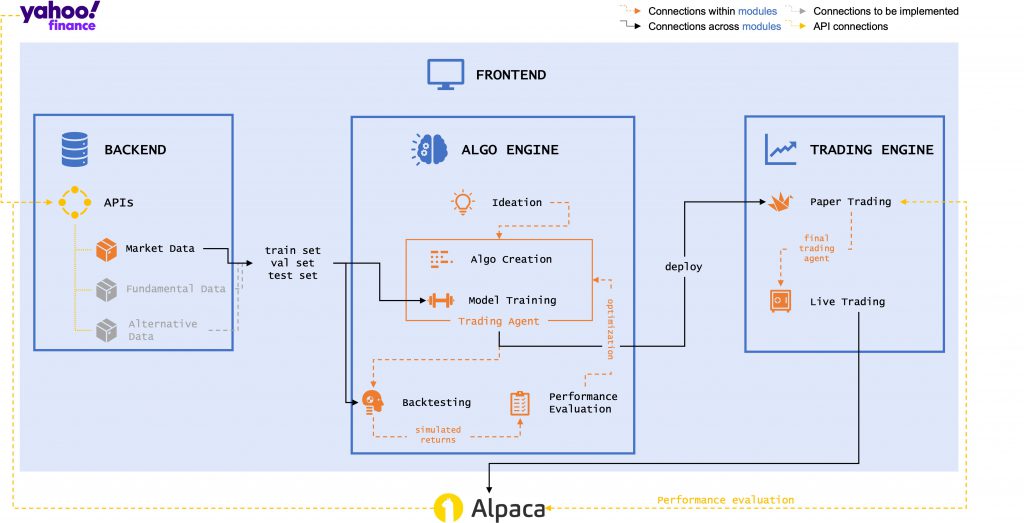
The idea of this article is to give a brief overview of each of these modules and which tools / libraries I am choosing going forward. Upcoming articles will then go into much more detail on how to build up / work with these tools.
2. Backend - Securities Master Database
Arguably the most boring part of a tech stack, but nonetheless indispensable – without available, clean and high quality data, there is no algorithmic trading.
For my Securities Master Database (SMD), I decided to go with a simple MySQL database that runs locally on my dev setup. I have plans on hosting this SMD on an always-on Raspberry Pi sometime in the future to have remote access without cluttering my disc.
Getting said high quality market data still poses a challenge to this date. Due to my student status, I have access to Bloomberg and Thomson Reuters at my university, but since my golden student days are coming closer to their end, I don’t want to be dependent of these paid services in the future. Another popular source of data is Yahoo Finance, which I already have some experience with – good and bad. Other data vendors such as Alpaca provide relatively easy to access data via their API, but mostly only for US equities and over a limited timeframe.
This leads me to the main problem: deciding on a stock universe to include in the SMD. As already mentioned, data providers such as Alpaca offer very high quality ticker data for thousands of stocks and ETFs, but only from the US. Yahoo Finance offers data for nearly every stock, but requires a very tedious and often times somewhat manual setup.
I will go into more detail about these issues in the dedicated blog post about the SMD, but for now, I will stick with a combination of the Yahoo Finance and the Alpaca API.
3. Algo Engine - From Ideation to Performance Evaluation
3.1. Algorithm Creation & Model Training
This is where it gets exciting! The algorithm or model is the brain of the trading engine and is responsible for issuing buy/sell signals on some predetermined criteria (algorithm) or on its own (artificial intelligence).
There is a wide variety of established trading strategies that can easily be translated into an algorithmic program. Websites such as Quantocracy, Quantpedia, QuantNet, QuantStart, Quantivity, and Quant Stackexchange provide more than enough material and (pseudo-)code to get started. Though not necessarily specialized on the quantitative finance / algorithmic trading domain, Papers with Code can also be a valuable resource.
I am planning on first translating some simple trading strategies such as the Golden Cross or RSI into code and then gradually moving on to more complex strategies as well as developing my own. Once I’m comfortable with these ‘hardcoded’ strategies, I want to explore the usability of machine / deep / reinforcement learning models for automatic strategy generation.
3.2. Backtesting & Performance Evaluation
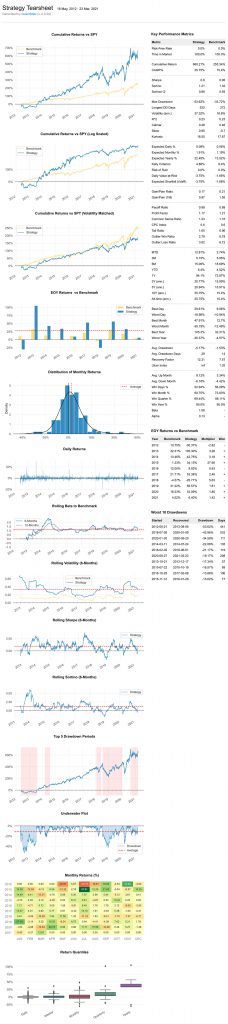
This part of the quant stack is all about testing the actual performance of a strategy and comparing its key metrics such as annual returns, Sharpe Ratio and volatility to those of a given benchmark (most often an index such as the S&P 500).
The python library Backtrader is well-suited for this task and can generate beautiful charts as the one below about a strategy’s execution & portfolio development. Plus, Backtrader is very well documented and integrates nicely with Alpaca. An alternative would be VectorBT.
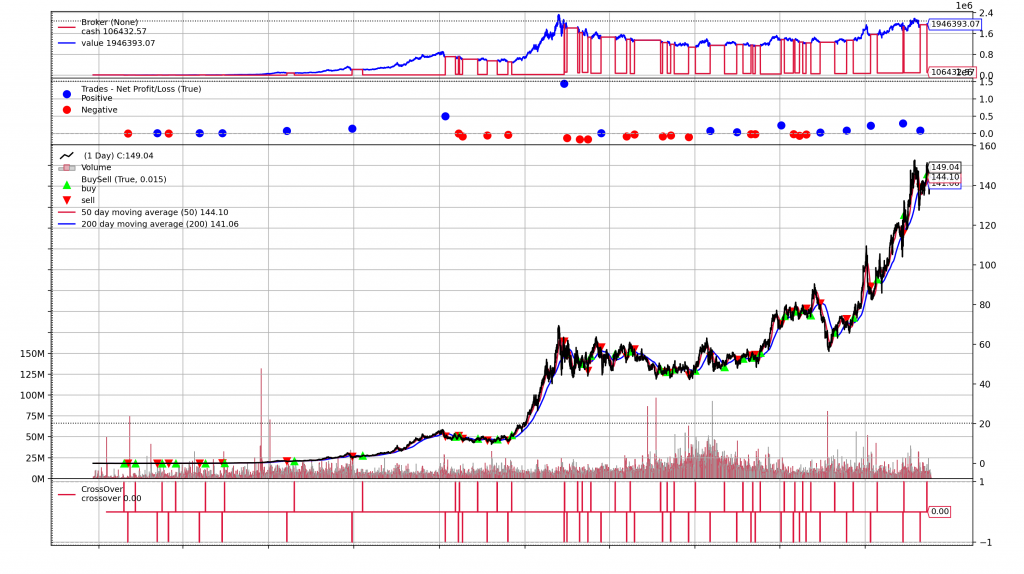
For advanced portfolio analytics, I will be using QuantStats, a package by the legendary Ran Aroussi who has also written the yfinance library that I make heavy usage of for my backend. PyFolio would be an alternative here.
4. Trading Engine - Paper & Live Trading
After a strategy has been thoroughly tested and refined on historical data, the next step involves connecting the trading engine to a paper trading / virtual portfolio API to test its performance in the real world. Probably the easiest solution here is again the Alpaca API which allows for free-of-charge algorithmic papertrading.
The ultimate goal of building up this Full Quant Tech Stack is getting the trading bot live and letting it trade with real money for (hopefully) positive returns. Unfortunately, Alpaca which has been such an easy and comfortable use for the previous steps, does not let non-US citizens issue real transactions via their API. Thus, when the time comes and my first promising trading bot can go live, I will have to find another broker (maybe Interactive Brokers) that works for my purposes. But I have the feeling that this issue still lies far in the future and I will have gathered much more experience and knowledge until then!
5. Frontend - Data Exploration (Optional)
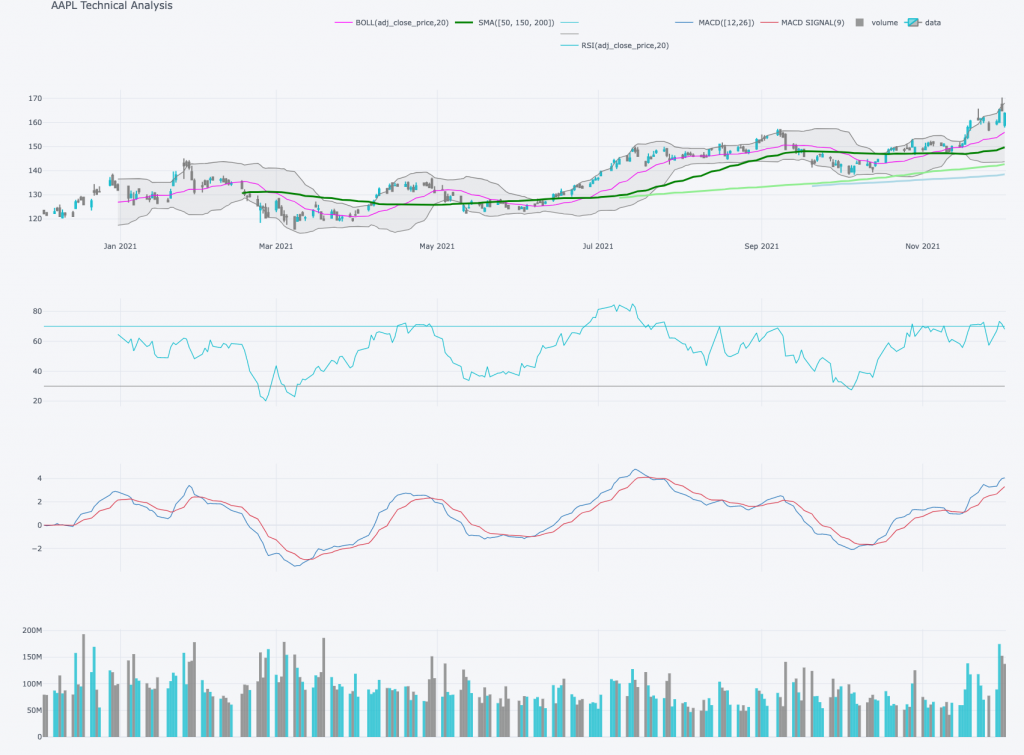
While tools such as MySQL Workbench already facilitate interacting with the backend, it is relatively easy to build a frontend web-application for data exploration with libraries such as FastAPI. I’m not completely sure yet which elements to include in a potential frontend, but for one: dynamic charts for technical analysis, generated via the cufflinks library.
6. Ready, Set, Code!
With these tools set in stone (at least for now), I will begin my Quant Finance / Algotrading coding journey! I will do my best to learn as much as I can as well as documenting my successes, failures and learnings. I am looking forward to you joining me in this exciting adventure!
Thank you for reading 🙂
Cheers, Niklas