Factor Momentum & Mean Reversion in Multifactor Investing

So far, my ventures into the world of quantitative finance were barely scratching the surface of real practitioners work. Toying around with the Securities Master Database and some algorithmic trading strategies with Python libraries such as Backtrader or VectorBT was a fun and easy way to familiarize myself with the most basic coding concepts within this field, but it was far from being professional or realistic. Thus, I was enthusiastic when I got the opportunity to join the AI quant hedge fund Quantumrock together with a study colleague of mine and work full-time on a real academic research project.
For the next three months, we worked on a quantitative trading strategy proposed by Quantumrock’s Chief Investment Officer about potential mean reversion effects in factor momentum investing. Since our study program allows for such project studies to be included in our degree, we additionally got supervision from TUM’s Chair of Financial Management & Capital Markets.
Below, you can download the PDF of our research paper that summarizes our collective work and findings.
If you’re interested, the following sections will go into more detail about the theory behind the proposed strategy, our implementation as well as results, limitations and some further outlook. Likewise, if you have questions or comments about our paper, feel free to contact me or Tobias via the provided mail addresses. Lastly, if you’re using our paper for your own research or publication, please remember to give us credit, e.g. via:
Baier, N., & Baldauf, T. (2022). Factor Momentum and Mean Reversion in Multifactor Investing. Unpublished manuscript.
Retrieved from https://niklasbaier.github.io/me/factor-momentum-and-mean-reversion-in-multifactor-investing/
1. Theory
Factor Investing is an established practice in quantitative asset management and aims at harvesting risk premia of well-documented and academically studied market anomalies. Probably the most well-known factor model is that of Fama and French, explaining the cross-section of asset returns via three factors:
- the excess return of the market over the riskfree rate
- the Size Premium SMB (Small Minus Big): small companies outperforming large companies
- the Value Premium HML (High Minus Low): high quality companies (characterized by a high book-to-market ratio) outperforming low quality companies
Since this revolutionary approach, a plethora of such risk factors has been identified and studied by academia with the momentum factor UMD (Up Minus Down) as one of the most robust and profitable across time, markets and asset classes. In the following years, momentum has thus been studied comprehensively and its core idea of recently well-performing stocks continuing their uptrend (and recently bad performing stocks continuing their downtrend) has been transferred to more abstract levels, such as industries or factors themselves. For our study, we first took a more detailed look at factor momentum by itself and then as a basis for the mean reversion strategy.
We can generally determine well/bad performing factors (winners/losers) two ways:
- a comparison of all factors in question against each other via their cross-section of returns (Cross Section Factor Momentum, CSFM)
- a comparison of each factor individually against its own time-series of returns (Time Series Factor Momentum, TSFM)
Below figure illustrates how factor momentum winners and losers can be determined for CSFM (cutoff value is the median return of all factors, i.e. every factor with returns above the median is considered a winner, and below the median a loser) and TSFM (cutoff value is 0, i.e. every factor with returns above 0% is considered a winner, and below 0% a loser).
Note that we have to shift the trading signals one time-step into the future to accommodate for the look-ahead bias (at the beginning of the timestep t, we do not know the factor returns at the end of the timestep).
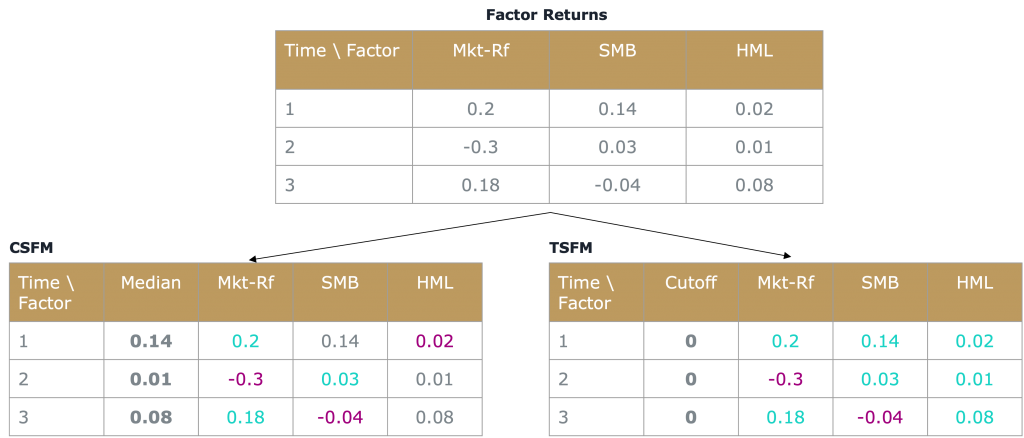
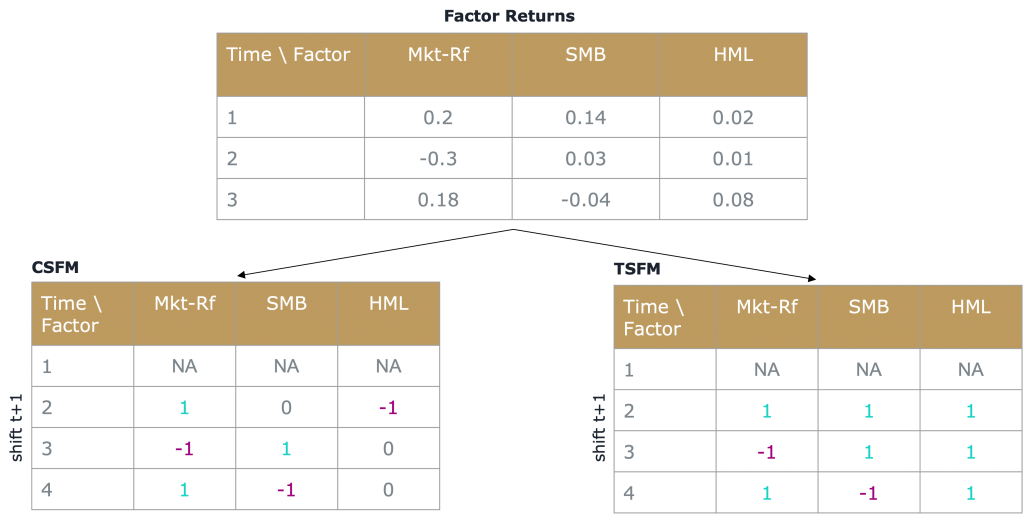
Above illustration showcases quite well the differences between these two strategies. Whereas CSFM always goes long and short in the same amount of factors, TSFM sometimes might be completely long or short, depending solely on the past returns of its underlying factors.
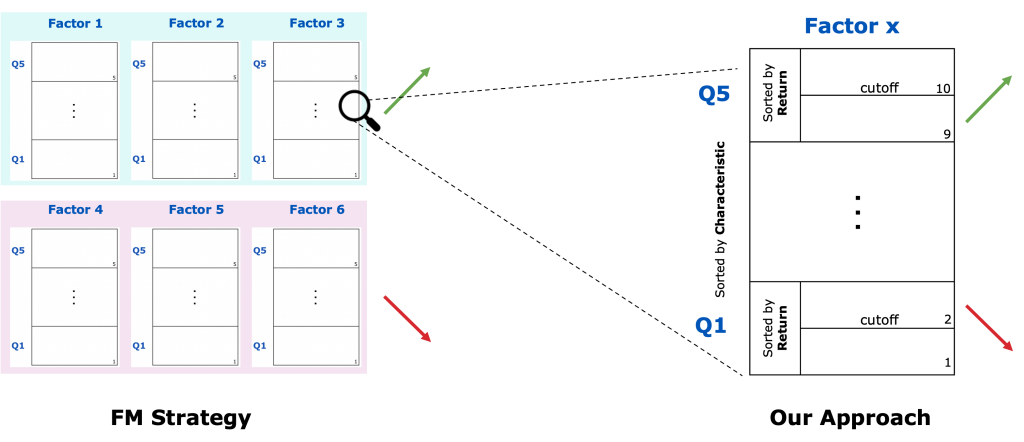
A normal factor momentum strategy would go long in every factor that has been determined a winner (either via the CSFM or TSFM approach) and go short in every loser, effectively trading the spread between these winner and loser portfolios. Investing in a factor also encompasses a long leg (those securities in the top quantile of the characteristic-sorted factor) and a short leg (bottom quantile), which effectively leads to trading a spread yet again. Our mean reversion approach zooms in on every factor and sorts the securities within the top and bottom quantiles again, but this time after their previous timestep’s return. We then go long in the bottom half of the top quantile, expecting those securities to showcase a reversion to the quantile mean return in the next timestep, i.e. an extraordinary performance. Vice versa, we go short in the top half of the bottom quantile, effectively betting on a large drop in performance in the next timestep. The return is then made up of the spread between these two subportfolios. We repeat this security selection process for every factor within the factor momentum winners, as well as the factor momentum losers, ultimatively trading the spread between these portfolios. Thus, the factor momentum based mean reversion strategy is a self-financing, long-short strategy.
2. Implementation
In order to properly research the proposed trading strategy, we built up a large Python research environment as illustrated in below figure.

We stored the data that was given to us from Quantumrock’s Heads of AI Systems and Algorithmic Trading in a numpy tensor for quick and efficient access. We built Jupyter Notebooks for each major step of the research process, i.e. Data Preprocessing (loading, cleaning, storing), Factor Momentum (strategy composition, grid search), Statistical Analysis (statistical measures of risk and performance, regressions), Portfolio Optimization (Monte Carlo simulations, linear optimization), and Robustness and Implementability (robustness measures, turnover, transaction costs). These notebooks mainly served as anchor points and place for visual output of the underlying code that was outsourced into roughly 100 functions within the Python files. In the end, we wrote nearly 3,000 lines of code and worked with more than 2,000,000 data points.
2.1. Factors
We worked on the S&P 500 universe over the timeframe of 20 years (06/2001 – 06/2021) and a total of 10 factors which could be grouped into five distinct categories: Size, Value, Quality, Dividends and Other.
| Category | FactSet Acronym | Description |
|---|---|---|
|
Size |
FREF_MARKET_VALUE_COMPANY |
Market Value |
|
Value |
FF_PE |
Price to Earnings |
|
FF_PSALES |
Price to Sales |
|
|
FF_PBK |
Price to Book |
|
|
Quality |
FF_ROA |
Return on Average Assets |
|
FF_ROTC |
Return on Average Invested Capital |
|
|
FF_ROE |
Return on Equity |
|
|
Dividends |
FF_DIV_YLD |
Dividend Yield |
|
FF_DPS |
Dividends per Share |
|
|
Other |
FSI_DAYS_ANY_EXCHG |
Short Interest Ratio |
For each ticker that has been part of the S&P 500 index over the past 20 years (924 in total), we stored its ISIN, price, return and factor characteristics. An additional variable act specified whether the ticker was part of the index at that particular date (act = 1) or not (act = 0). This was very important to avoid the pitfall of the survivorship bias. You can imagine the data as sheets for each ticker (z-axis) with the time on the y-axis and the data columns on the x-Axis. For the rest of the study, we used monthly log returns since they closely resembled a normal distribution and made the calculation of cumulative and annualized return metrics straightforward.
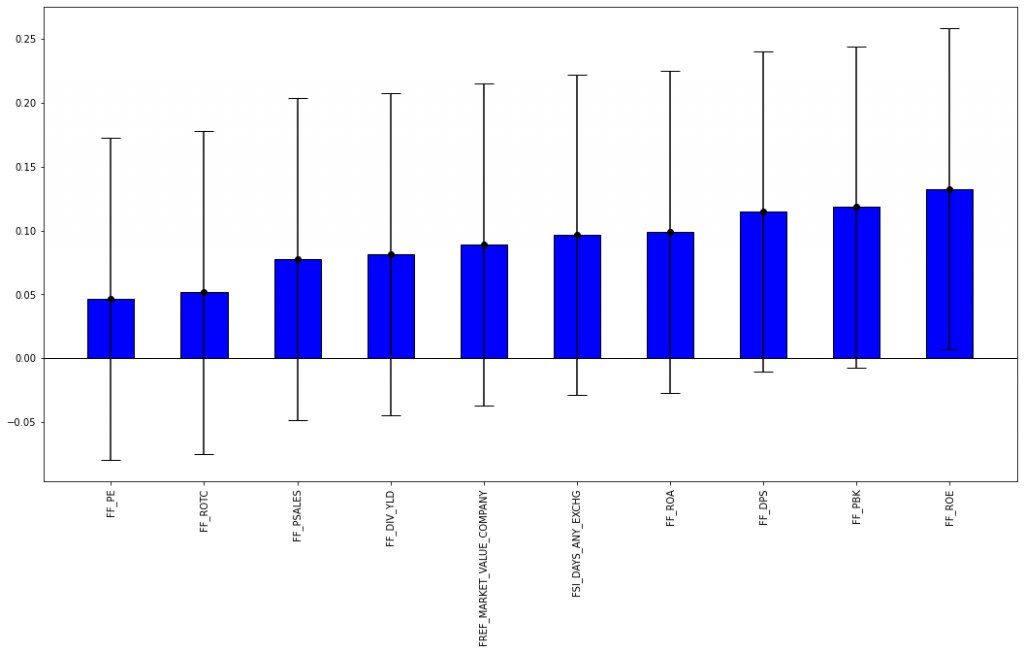
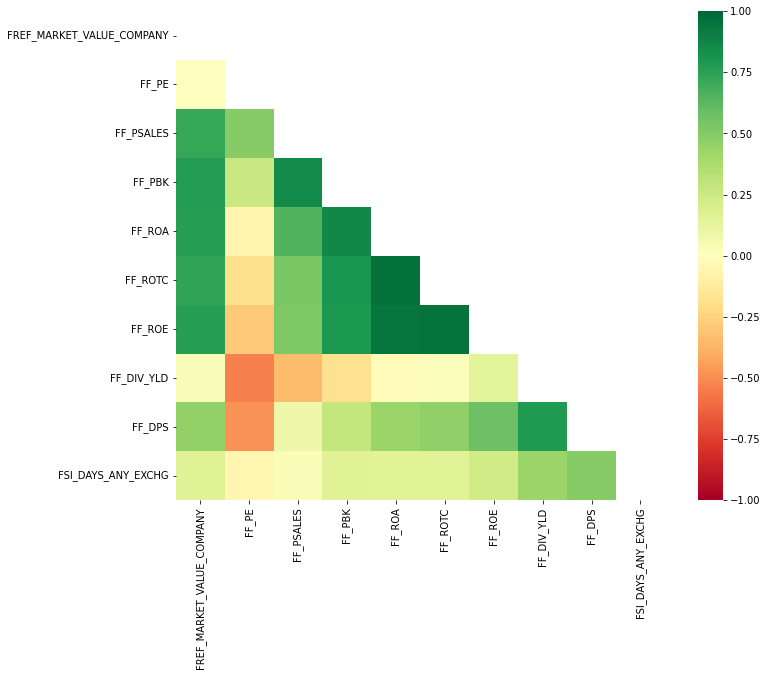
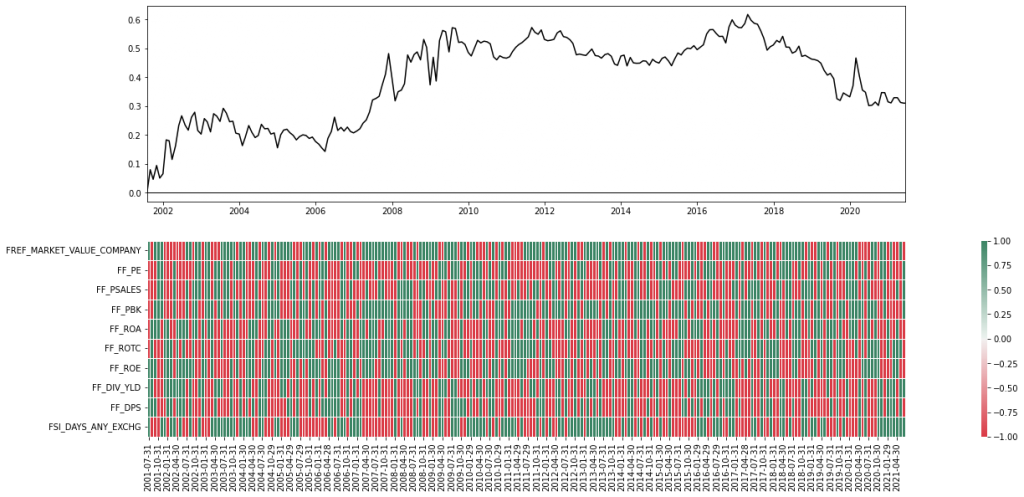
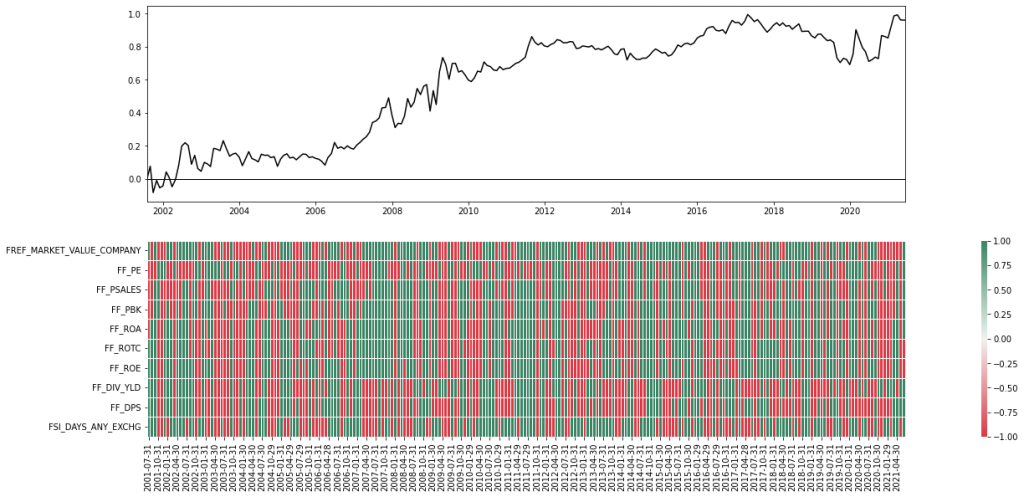
After the initial preprocessing was done, we dove a bit deeper into the statistics of our factor sample. Below figures illustrate the monthly first-order autoregressive coefficients (left) and the correlation between the individual factors (right). We can see that a factor’s previous return is somewhat informative about its future return since all AR(1) coefficients were positive. However, this observation was only statistically significant for one of the 10 factors. Furthermore, most of the factors seemed to be highly correlated, which should come at no surprise since we were using very similar metrics and ratios that were partially constructed from the same underlying (pricing) data.
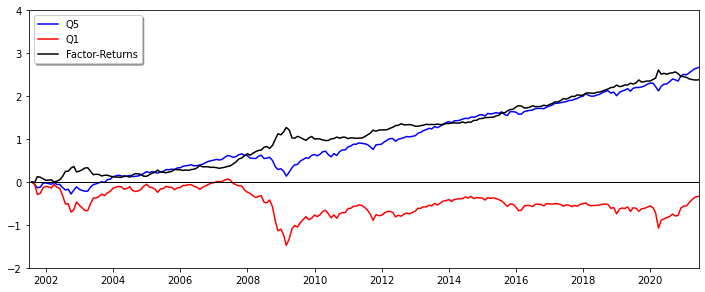
We formed factors by sorting the investment universe after the corresponding factor characteristic (large to small) and then determined the top and bottom (Q5 and Q1) quantiles. Quantile returns were calculated as the average returns over all included securities (equal weights) and the final factor return was determined via the spread (black) between the Q5 (blue) and the Q1 (red) quantile returns (long in Q5, short in Q1). Most of the factor returns were distributed around zero, with the exception of FREF_MARKET_VALUE_COMPANY, FF_DPS and FSI_DAYS_ANY_EXCHG.
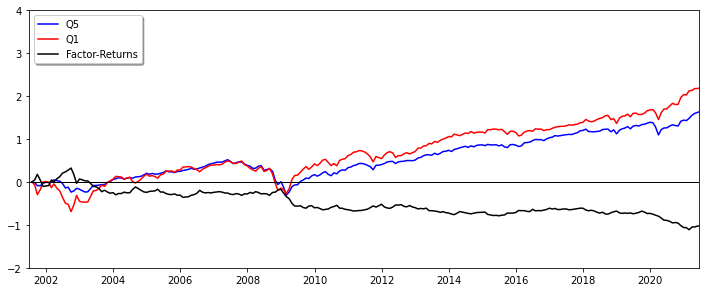
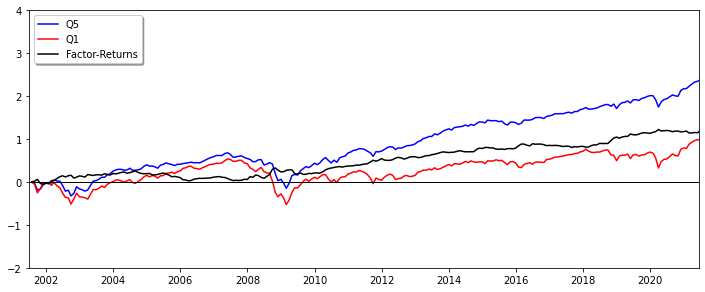
2.2. Factor Momentum
We constructed simple, plain vanilla (PV), versions of CSFM and TSFM with the following attributes:
- holding period: 1 month (monthly rebalancing)
- formation period: 1 month (trading signal is constructed from past month’s return)
- cutoff value: 0.5 (median) for CSFM, 0% for TSFM
CSFM_PV
| formation | cutoff | E[R] | STD | Sharpe |
|---|---|---|---|---|
|
1 month |
0.5 |
1.55% |
11.41% |
0.14 |
TSFM_PV
| formation | cutoff | E[R] | STD | Sharpe |
|---|---|---|---|---|
|
1 month |
0% |
4.80% |
15.12% |
0.32 |
For the plain vanilla versions, we fixed the formation period and cutoff values but we were curious to see whether different values would lead to better results (in terms of Sharpe ratios). Thus, we defined a small grid search environment that calculated strategy permutations for every possible combination of formation periods (1, 3, 6, 9 and 12 months) and cutoff values (0.1, 0.2, 0.3, 0.4 and 0.5 for CSFM; 0%, 0.5%, 1% and 1.5% for TSFM). Holding periods were kept constant at 1 month to keep the notion of monthly rebalancing.
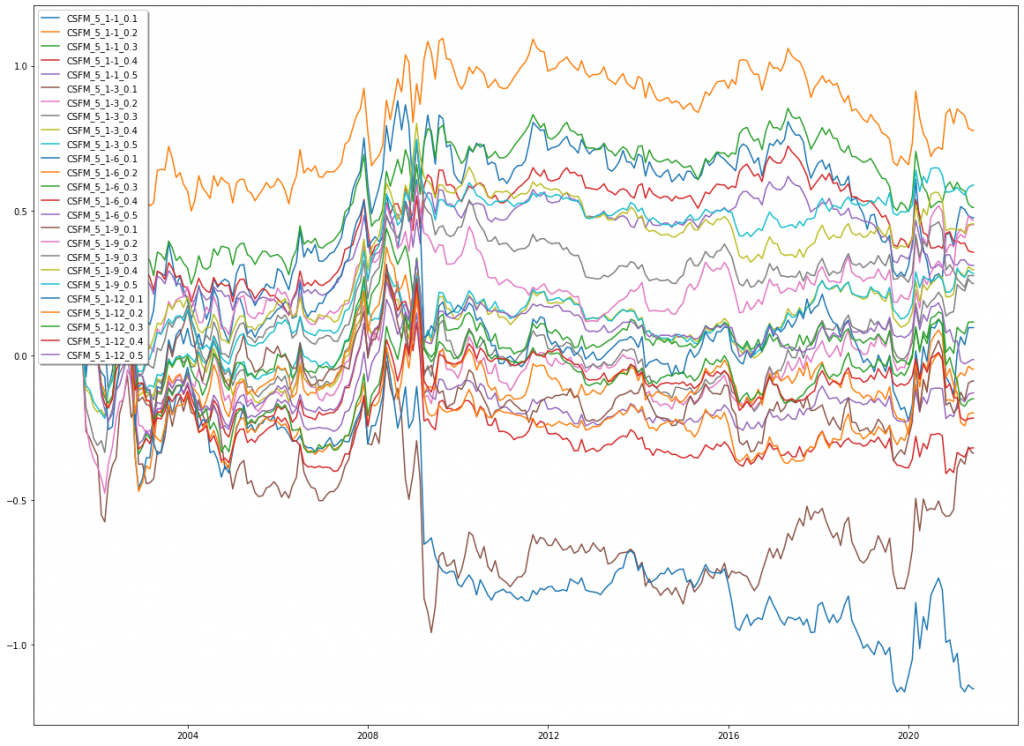
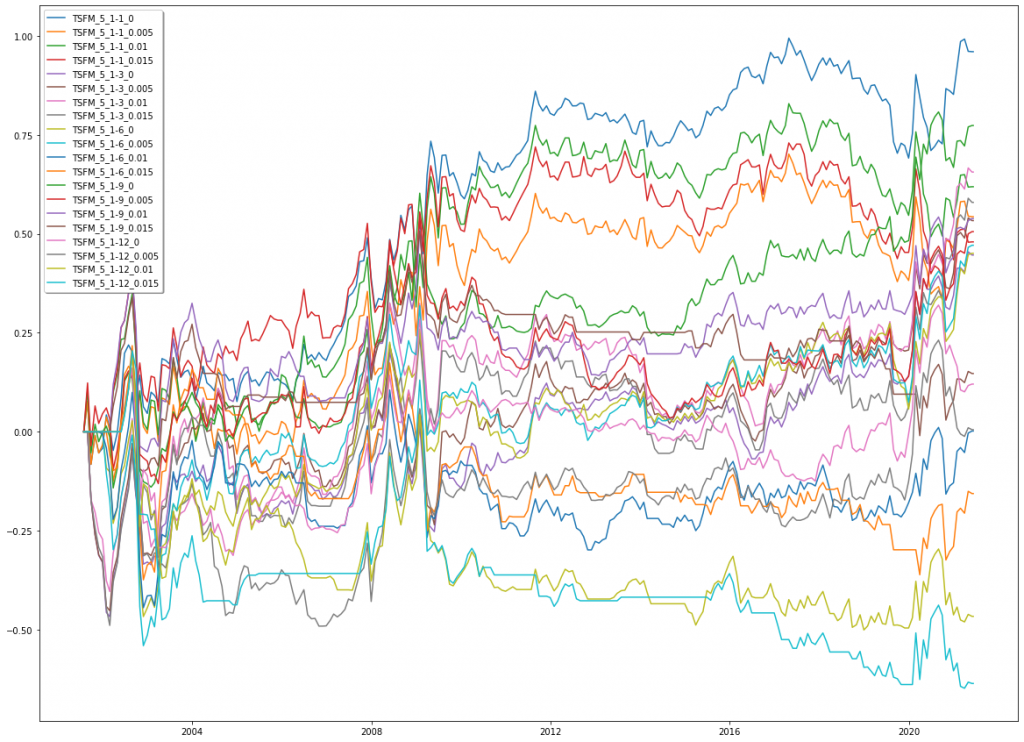
From the result space we then chose the best Sharpe (BS) versions for further consideration. TSFM_BS coincidently turned out to have the same parameter values as TSFM_PV, but for consistency’s sake, we kept both versions separately. Otherwise, Sharpe ratios slightly improved but we could not find any real patterns in parameter values that would lead to reliably better performance.
CSFM
TSFM
CSFM_BS
| formation | cutoff | E[R] | STD | Sharpe |
|---|---|---|---|---|
|
9 months |
0.5 |
2.94% |
11.63% |
0.25 |
TSFM_BS
| formation | cutoff | E[R] | STD | Sharpe |
|---|---|---|---|---|
|
1 month |
0% |
4.80% |
15.12% |
0.32 |
2.3. Mean Reversion
For the mean reversion strategies, we also first defined plain vanilla versions that fixed the parameters at one month for formation and holding periods, the cutoff values for the underlying factor momentum strategies at 0.5 and 0%, and finally the cutoff within the factor quantiles at 0.5 (i.e. split the return-sorted Q5 and Q1 quantiles in half and go long/short in the lower/upper half of the Q5/Q1 quantile).
Below illustration shows the mostly negative performance of MRCSFM_PV and MRTSFM_PV. These strategies only performed well during crises such as the financial crisis in 2008/09 or the COVID crisis in 03/2020 but were not able to keep their profits once the market started rallying again. This led us to believe that the factor momentum based mean reversion strategies could rather function as tail-hedge strategies that add value to a larger set of investment strategies in these kind of three and more sigma events.
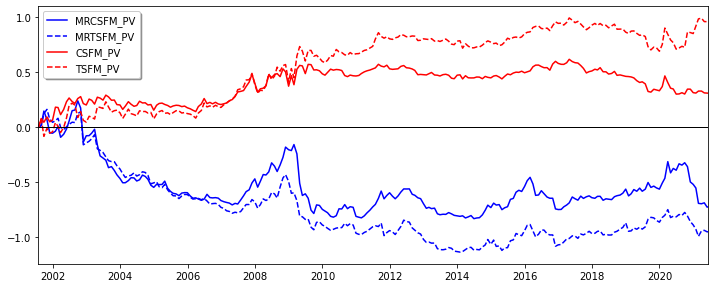
| formation | cutoff FM | cutoff MR | E[R] | STD | Sharpe | |
|---|---|---|---|---|---|---|
|
MRCSFM_PV |
1 month |
0.5 |
0.5 |
-3.62% |
17.60% |
-0.21 |
|
MRTSFM_PV |
1 month |
0% |
0.5 |
-4.75% |
14.14% |
-0.34 |
Next, we yet again performed a grid search on a number of tunable parameters:
- Factor Momentum: formation period [1, 3, 6, 9, 12]; cutoff values [0.1, 0.2, 0.3, 0.4, 0.5] for CSFM / [0%, 0.5%, 1%, 1.5%] for TSFM
- Cutoff Value: [0.1, 0.2, 0.3, 0.4, 0.5]
- Strategy Permutations: 18 versions (long-short, long-only, short-only, winner-only, loser-only, …)
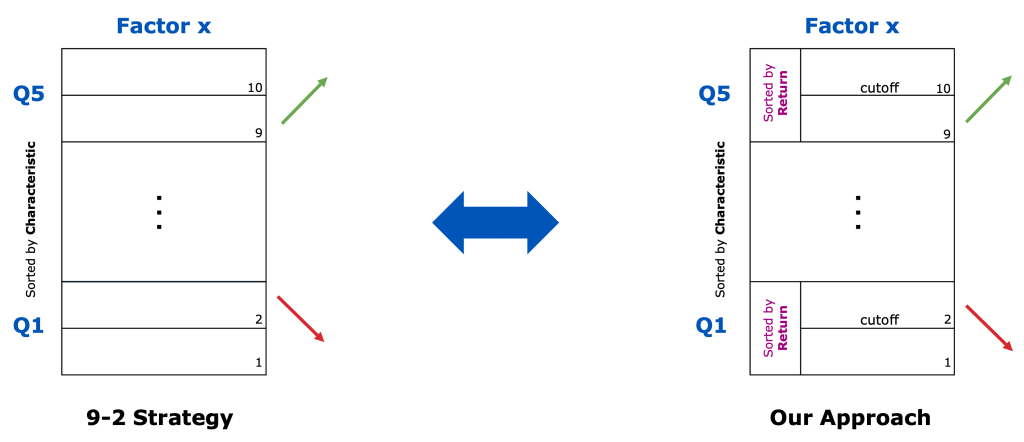
- True Mean Reversion (Q5 and Q1 quantiles sorted by return) vs. 9-2 Strategy (Q5 and Q1 quantiles sorted by factor characteristic)
In one of our feedback sessions with our academic supervisor, the question of how our mean reversion approach differed from a conventional 9-2 strategy arose. The main difference lies in the additional re-ordering of the top and bottom quantiles for the mean reversion approach. A 9-2 strategy simply divides the ticker universe that has been sorted after the respective factor’s characteristic into 10 deciles (instead of five quantiles) and goes long in the 9th and short in the 2nd decile. Our mean reversion strategy sorts the securities within the Q5 and Q1 quantiles again after their return in the previous timestep. For a cutoff value of 0.5, we then go long in the 9th and short in the 2nd decile. If there was some sort of reversion to the mean effect, this additional re-sorting should theoretically lead to higher risk-adjusted returns than those of the 9-2 strategy.
We found, however, no real difference between the performance of these two kinds of strategies leading us to conclude that it does not matter whether the quantiles are sorted again after return, or not. There were no significant reversion to the mean effects to be found in our underlying data, at least for monthly rebalancing.
| Average Results | E[R] | STD | Sharpe | Range(Sharpe) |
|---|---|---|---|---|
|
sorted by Return |
1.12% |
19.36% |
0.07 |
1.40 |
|
sorted by Factor Characteristic |
1.89% |
15.33% |
0.11 |
1.66 |
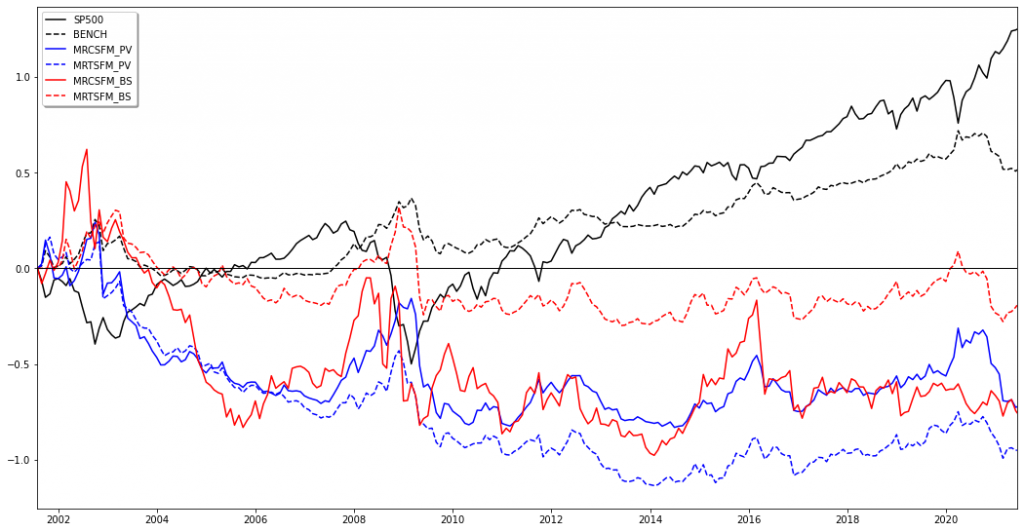
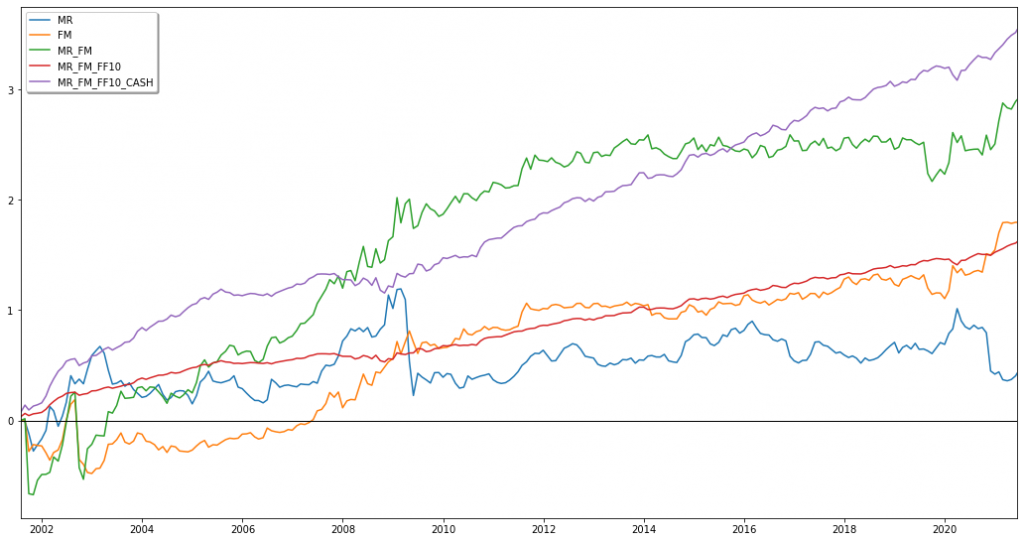
Below figure compares the performance of both plain vanilla and best Sharpe versions of factor momentum based mean reversion against the S&P 500, as well as a naïve benchmark (BENCH) that simply went long in every factor (equally weighted) at the beginning of the timeframe and held its position until the end. The performance of the S&P 500 remains unmatched, it is just in times of extreme market turmoil that our strategies achieved large positive returns (at the cost of large overall volatilities).
This result strengthened our interim conclusion from above that the mean reversion strategies are better not used as stand-alone trading strategies but could rather function well as crisis alpha add-ons in larger investment portfolios. It is for this reason that we decided to examine in the next step how portfolio optimizers would weight our strategies when combined with other options.
| formation | cutoff FM | cutoff MR | E[R] | STD | Sharpe | |
|---|---|---|---|---|---|---|
|
MRCSFM_BS |
1 month |
0.1 |
0.1 |
-3.77% |
30.85% |
-0.12 |
|
MRTSFM_BS |
6 months |
0% |
0.4 |
-0.96% |
14.48% |
-0.07 |
Finally, we performed some linear regressions of our factor momentum (CSFM_PV, TSFM_PV, CSFM_BS, TSFM_BS) and mean reversion (MRCSFM_PV, MRTSFM_PV, MRCSFM_BS, MRTSFM_BS) strategies over the S&P 500, the Fama-French Five Factor Model, and an extended version that additionally included popular risk factors such as UMD, STR, LTR, BAB and QMJ. The more factors we included in the regression, the more amplified the effects became:
- Factor momentum alphas were small, but positive (non-significant)
- Mean reversion alphas were negative (and partly statistically significant)
3. Additional Work & Analysis
3.1. Portfolio Optimization
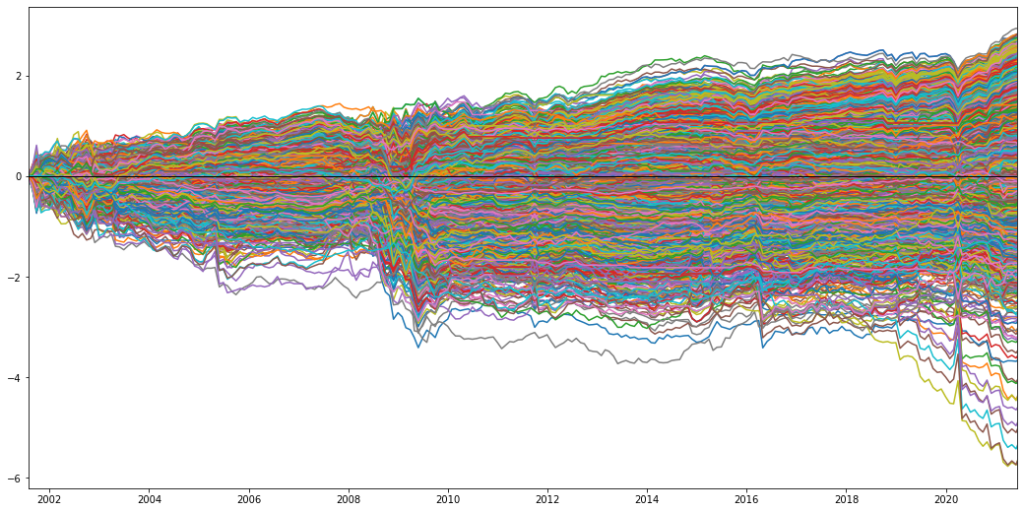
We performed a Monte Carlo simulation that formed 1,000,000 portfolios with random weights in the four factor momentum and four mean reversion strategies (long-only, weights have to sum up to one). Each of these portfolios is illustrated as a blue dot in below figure and placed according to its risk-return characteristics. The red dashed line resembles the Efficient Frontier, i.e. those portfolios with the highest return for a given level of risk. The red and green stars resemble the Minimum Variance Portfolio (MVP) and the Tangency Portfolio (TP), respectively. The MVP naturally placed its largest weights in those strategies with the lowest risk (standard deviation) and the TP overweighted those with the highest Sharpe ratio.
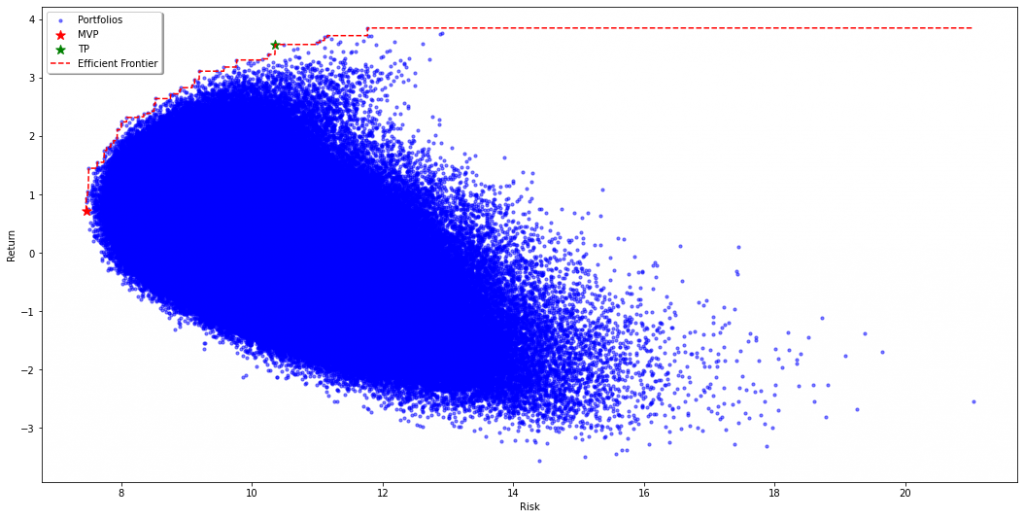
These simulated portfolios already gave a good approximation of how our eight strategies could combine into an optimized portfolio. We wanted to corroborate these results by running a linear optimization program on a set of different portfolio choices:
- all four mean reversion strategies
- all four factor momentum strategies
- all eight mean reversion and factor momentum strategies (a)
- a + all factors from the extended factor model from above (b)
- b + cash as a riskfree investment
long-only
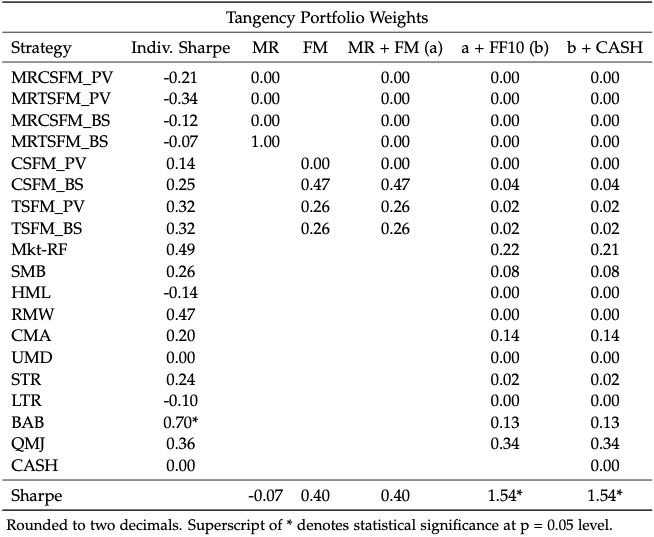
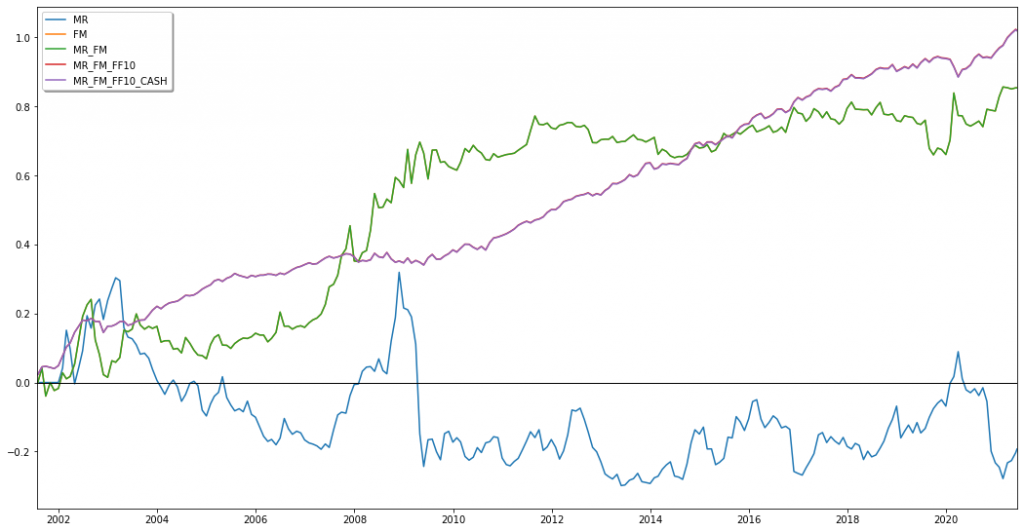
long-short
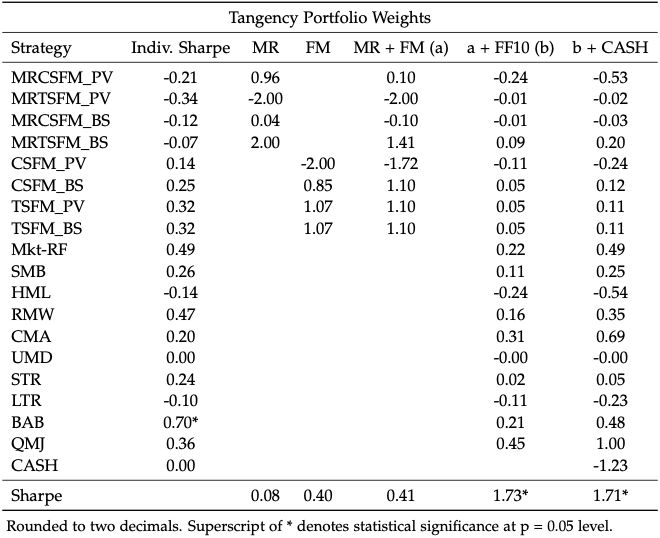
From this, we were able to deduce two main findings:
- mean-variance optimization is a powerful tool to increase the Sharpe ratio of a portfolio, even if its individual constituents have negative or very small Sharpe ratios
- the mean reversion strategies are either avoided (long-only) or primarily shorted (long-short) to finance leveraged positions in the other options
3.2. Robustness & Implementability
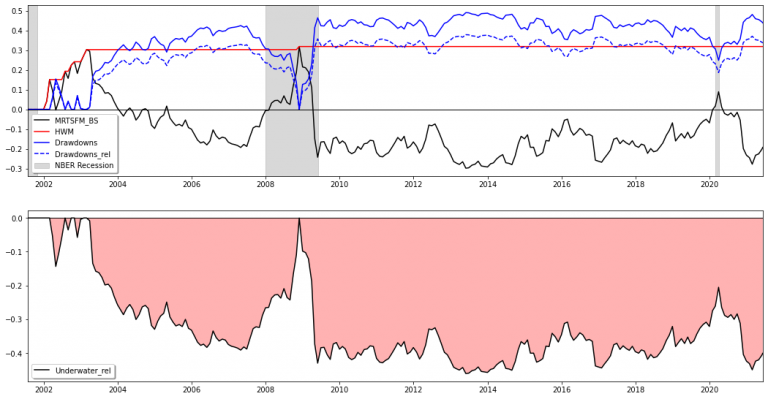
Following the portfolio optimization, we took a look at various robustness measures such as drawdowns, excess returns over the S&P 500, tracking errors and information ratios with regard to the S&P 500, as well as value at risk and expected shortfall figures. The following illustration visualizes exemplarily the High Water Mark (cumulative max. returns), that is often times used as a threshold for hedge fund performance fees, of the MRTSFM_BS strategy.
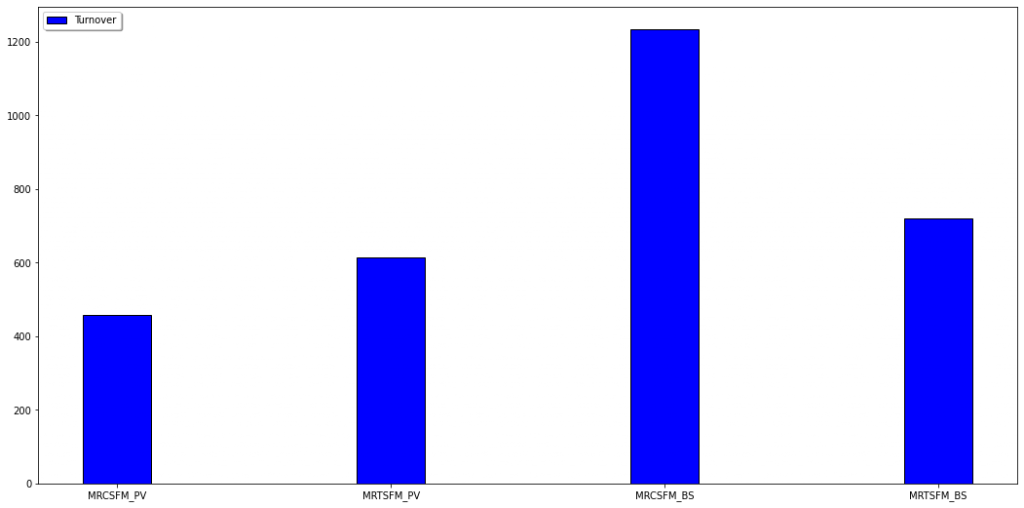
Up to this point, we calculated strategy returns on the factor level. In practice, however, algorithmic trading schemes need to work on the lowest, ticker, level in order to properly generate buy and sell orders. We thus went ahead and built a Ticker-based Backtest that enabled us to determine each individual ticker’s weight for each strategy at every point in time. This not only verified our previous, more meta level, calculations, but also opened up the possibility to calculate the turnover of a particular strategy. From there, we could then estimate transaction costs, incurring 10 basis points for every unit of turnover.
Below figure displays the turnover (left) and the four mean reversion strategies, before cost (BC) and after cost (AC) (right).
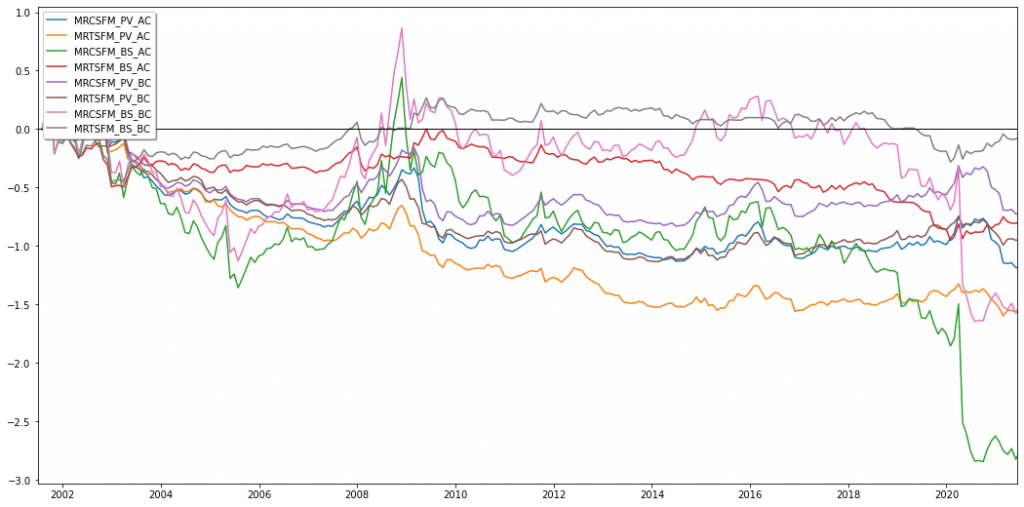
Lastly, we were curious to see whether we could identify some industry trends within our mean reversion strategies and indeed, it seemed that they mostly invested into the same industries. For the plain vanilla versions, we could even identify some clear troughs (short) and spikes (long), whereas loadings for the best Sharpe versions were distributed rather equally over all industries.
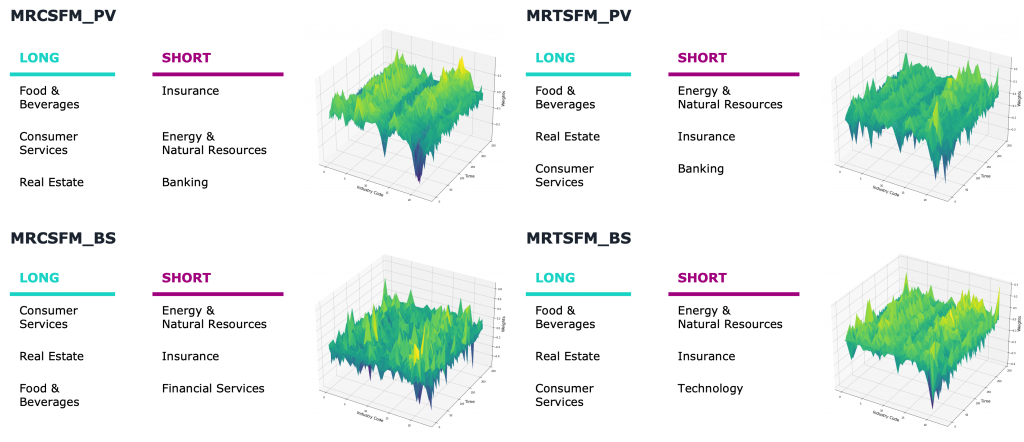
4. Limitations & Outlook
As it is always the case with academic research, we had to make assumptions and were prone to a number of limitations:
- S&P 500 investment universe (only 924 tickers in total; only ~500 tickers per timestep; biased in size, liquidity, profitability, …)
- Post 2000 era (markets more efficient & liquid; diminishing anomaly returns)
- Highly correlated factors (only five distinct risk factor groups; only 10 * 240 months = 2,400 data points)
- no statistical significance of returns (factor returns & autocorrelations mostly unsignificant; strategy returns mostly unsignificant)
5. References & Data Sources
Please view the corresponding chapter in the paper for a list of the underlying sources. Data has been taken from FactSet, the Kenneth R. French website, AGI’s website and FRED.
6. Learnings
My three months at Quantumrock went by in a flash, but at the same time it felt like I was getting a year’s worth of experience. Time and time again I am fascinated by how much one can learn in such a short amount of time. Before this project study, I was only familiar with the very basics of factor investing from theoretical university courses and now, three months later, I am confident in both, my understanding and practical skills, to develop, code, and test factor investment strategies.
Furthermore, it was the first time for me to work together with others on a code base this large, demanding not only the ability to read, understand and work with code that I have not written myself, but also to “let go” of wanting to do everything “my way”. On top of that, I was forced to brush up my git skills for usage other than simply backing up code to a GitHub repository (I am looking at you, git merge!).
Since we also got supervised by a chair of our university, researching this topic had to be done in a very clean and academic matter. This not only determined how we built the strategies and backtested them, but also required reading many academic papers and creating figures and illustrations on publication level. Actually, we wrote nearly 900 lines of code just for the various charts and plots! Our final paper was written in LaTeX which posed to be a challenge in of itself – but it resulted in a much more clean and “professional” look.
Taken altogether, this project study has been an invaluable experience and I am excited for what’s coming next.
As always, thank you for reading 🙂
Cheers, Niklas