Building up a Securities Master Database

This is the first big post in a series of detailed articles about building up a Full Quant Tech Stack. In the following, I will discuss my approach to building up a Securities Master Database (SMD) for storing corporate information and historical price data for a universe of financial instruments (mostly equities, but also ETFs, and maybe even derivates later on). I will go into detail about design choices in the database scheme, as well as different data vendors and their (dis-)advantages. I will also provide my code for me to retrace my steps in the future, as well as for the curious reader who may also want to build up their very own SMD.
I am by no means an expert on neither database design, nor coding in general, but I tried to keep everything as efficient as possible. If you find any mistakes in my logic or inefficiencies in my code, feel free to leave me a comment with constructive criticism 🙂
Finally, I didn’t natively come up with this approach to an SMD all by myself, but I am rather standing on the shoulders of giants, most notably this QuantStart article, Robert Andrew Martin from Reasonable Deviations, and Part Time Larry from Hacking the Markets. Their articles / videos were such a great and beginner-friendly guide to this endeavour and helped me a lot in understanding below concepts. Their ideas and code snippets served me well as a starting point for the first versions of my SMD. To make it my very own, I altered some passages here and there and expanded the scope in size and functionality.
With this post, I feel like it is time to give back to the community, so feel free to take my version of an SMD as your starting point. Without further ado, let’s get going!
1. What is a Securities Master Database?
An SMD is an organization-wide database that stores fundamental, pricing and transactional data for a variety of financial instruments such as equities, options, indices, forex, interest rates, futures, commodities, bonds and other derivatives across asset classes.
Datasets comprise end-of-day and / or intraday historical pricing for above-mentioned financial instruments, acquired via web-available APIs such as Yahoo Finance, Quandl, Alpaca, etc.
1.1. How is the data stored?
For financial data, Relational Database Management Systems (RDBMS) such as MySQL are particularly-well suited since they enable different objects such as exchanges, data vendors, instruments and prices to be separated into tables with relationships between them. Though I tried to design the database scheme in a future-proof way, there might be a time when I will have to update it nonetheless, e.g. when introducing a new table for fundamental data. Luckily, RDBMS can easily be modified to reflect such changes and new relationships between tables are quickly created. Similarly, a MySQL database allows for cascading deletion of data, i.e. not only the data but also its dependencies / relationships to other table entries will be deleted. Furthermore, RDBMS are relatively straight-forward to install, platform-independent, easy to query via SQL, easy to integrate with backtesting systems (such as Backtrader), as well as high performing at large scales.
1.2. How is the data structured?
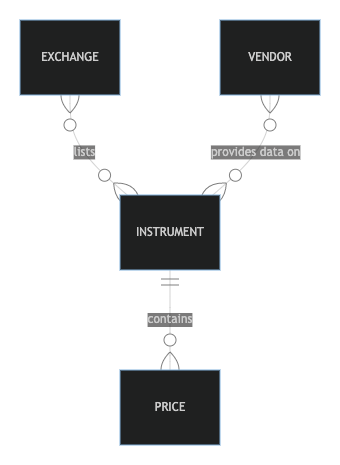
A common pattern for the construction of an SMD consists of the following entities (= tables in the database):
- Exchange (original listing of the instrument)
- Vendor (actual data source for a particular data point)
- Instrument (ticker / symbol for the financial instrument, alongside some key corporate information)
- Price (actual price in OHLCV format for a particular instrument on a particular day)
2. Prerequisites
Now that we know what an SMD is, let’s get into the details on how to actually create one. But first, there are some prerequisites.
2.1. MySQL Database Setup on Mac
I have already written a brief overview on how to setup a MySQL server locally in this post, so please refer to it for the initializing steps.
2.2. MySQL Database Setup on Raspberry Pi
For the time being, I will keep my SMD running locally on my Mac, but I definitely have plans on hosting it on an always-on Raspberry Pi server. Doing so will enable me (and others) to connect to a remotely hosted, shared database instead of only a local instance. See also the open issues section at the end.
2.3. Setting up Users
This step is not as important right now, but as soon as the database is accessed by people other than me, I will have to set up according user profiles. For now, I will access the local SMD as root.
2.4. Optional: MySQL Workbech as GUI
Since storing historical price data for a universe of financial instruments well into the ten-thousands will result in millions of row entries, it might be beneficial to set up a GUI client for manually looking up data from the database, e.g. when testing whether certain inserts have been successful. MySQL Workbench is an easy to use candidate for that.
To connect the client to your local MySQL server, just click on the + icon next to MySQL Connections > Setup New Connection.
|
Connection Name |
Securities Master Database |
|
Hostname |
127.0.0.1 (stands for localhost) |
|
Port |
3306 |
|
Username |
root |
|
Password |
Store in Keychain ... (type in root password of your local MySQL server) |
Now, click on Test connection. If this window pops up, you’re good to go and can click OK.
You can now access your database via the GUI client (as long as the server is running), e.g. to test out some SQL statements.
2.5. Requirements.txt
The following packages need to be installed (pip install -r requirements.txt) into your dedicated Python environment (for a primer on conda environments, click here):
alpaca_trade_api==1.4.1
cufflinks==0.17.3 lxml==4.6.3 matplotlib==3.4.3 numpy==1.21.3 pandas==1.3.3 pandas_datareader==0.10.0
plotly==5.3.1 PyMySQL==1.0.2 requests==2.26.0
seaborn==0.11.2 tqdm==4.62.0 yfinance==0.1.64
3. Generating the SMD
3.1. Database Schema
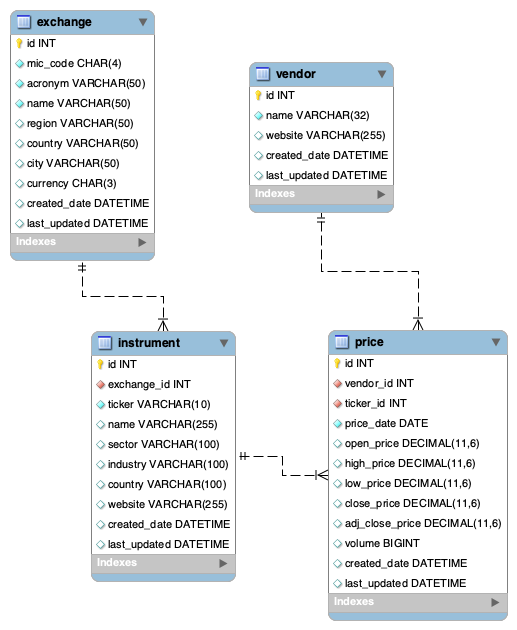
A database schema sets out how all of the information is going to be organized in the database. The following suggested schema does not make any assumptions about which financial instruments you are interested in and gives you the flexibility of adding any type of security as long as it can be represented as a time series of prices.
Referring back to section 1.2. How is the data structured?, the proposed scheme consists of four tables: exchange, vendor, instrument, and price.
|
exchange |
contains information of the exchange and is a parent table for instrument |
|
vendor |
contains information about the actual data source |
|
instrument |
holds all of the relevant (corporate) information about the actual companies / underlying for which data will be collected |
|
price |
holds OHLC, Adj. Close and Volume data for every ticker that is part of the instrument table |
For each table, the primary key is a distinct ID which assigns an unambiguous integer value to every tuple. This allows us to uniquely identify a specific entry in the table. For linking the four tables together, we will use foreign keys to refer to these uniquely identifying IDs.
3.2. Database & Table Creation
Now that the schema for the SMD has been conceptualized, you can setup the database and its tables on your MySQL server.
If not done already, start the server and log in (as root) via:
mysql.server start mysql -u root -p
Database
CREATE DATABASE securities_master; USE securities_master;
Table: exchange
CREATE TABLE IF NOT EXISTS `exchange` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `mic_code` CHAR(4) NOT NULL, `acronym` VARCHAR(50) NOT NULL, `name` VARCHAR(50) NOT NULL, `region` VARCHAR(50) NULL DEFAULT NULL, `country` VARCHAR(50) NULL DEFAULT NULL, `city` VARCHAR(50) NULL DEFAULT NULL, `currency` CHAR(3) NULL DEFAULT NULL, `created_date` DATETIME NULL DEFAULT CURRENT_TIMESTAMP(), `last_updated` DATETIME NULL DEFAULT CURRENT_TIMESTAMP() ON UPDATE CURRENT_TIMESTAMP(), PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8;
For every entry in our exchange table, we want to store an auto-incrementing id as primary key (referenced by the foreign key of the instrument table), the unique four-character Market Identifier Code (MIC) mic_code, as well as the acronym, name, region, country, city and currency of the exchange. Furthermore we will keep track of when an exchange has been added to the table (created_date) and when it has been updated (last_updated).
Table: vendor
CREATE TABLE IF NOT EXISTS `vendor` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(32) NOT NULL, `website` VARCHAR(255) NULL DEFAULT NULL, `created_date` DATETIME NULL DEFAULT CURRENT_TIMESTAMP(), `last_updated` DATETIME NULL DEFAULT CURRENT_TIMESTAMP() ON UPDATE CURRENT_TIMESTAMP(), PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8;
Similarly to above, for every data vendor in the vendor table, we keep its id as primary key (to be referenced by the foreign key of the price table). Additionally, we store the vendor’s name and website, as well as their date of creation and update.
Table: instrument
CREATE TABLE IF NOT EXISTS `instrument` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `exchange_id` INT(11) NOT NULL, `ticker` VARCHAR(10) NOT NULL, `name` VARCHAR(255) NULL, `sector` VARCHAR(100) NULL, `industry` VARCHAR(100) NULL, `country` VARCHAR(100) NULL, `website` VARCHAR(255) NULL, `created_date` DATETIME NULL DEFAULT CURRENT_TIMESTAMP(), `last_updated` DATETIME NULL DEFAULT CURRENT_TIMESTAMP() ON UPDATE CURRENT_TIMESTAMP(), PRIMARY KEY (`id`), INDEX `exchange_id` (`exchange_id` ASC), INDEX `ticker` (`ticker` ASC), CONSTRAINT `fk_exchange_id` FOREIGN KEY (`exchange_id`) REFERENCES `exchange` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8;
For the financial instrument table, we keep track of two unique identifiers: the instrument’s own id (you guessed it, its primary key to be referenced by the price table’s foreign key) and the id of the exchange that lists this instrument (foreign key of instrument that references exchange‘s id attribute). This allows us to uniquely identify a certain instrument listed on a certain exchange since it is not uncommon for securities to be listed on several exchanges.
For the actual information on the financial instrument / underlying, we store its ticker, name, sector, industry, country and website. Again, as before, we keep track on its created_date and its last_updated date.
Table: price
CREATE TABLE IF NOT EXISTS `price` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `vendor_id` INT(11) NOT NULL, `ticker_id` INT(11) NOT NULL, `price_date` DATE NOT NULL, `open_price` DECIMAL(11,6) NULL DEFAULT NULL, `high_price` DECIMAL(11,6) NULL DEFAULT NULL, `low_price` DECIMAL(11,6) NULL DEFAULT NULL, `close_price` DECIMAL(11,6) NULL DEFAULT NULL, `adj_close_price` DECIMAL(11,6) NULL DEFAULT NULL, `volume` BIGINT(20) NULL DEFAULT NULL, `created_date` DATETIME NULL DEFAULT CURRENT_TIMESTAMP(), `last_updated` DATETIME NULL DEFAULT CURRENT_TIMESTAMP() ON UPDATE CURRENT_TIMESTAMP(), PRIMARY KEY (`id`), INDEX `price_date` (`price_date` ASC), INDEX `ticker_id` (`ticker_id` ASC), CONSTRAINT `fk_ticker_id` FOREIGN KEY (`ticker_id`) REFERENCES `instrument` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_vendor_id` FOREIGN KEY (`vendor_id`) REFERENCES `vendor` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8;
Whereas the other tables mainly exist to keep some meta information about the companies in our asset universe, the price table actually holds the time series data and will be by far the largest table in the SMD.
To distinctly assign a history of price data for a specific security, listed on a specific exchange with data from a specific vendor, we keep three identifiers (id, vendor_id, ticker_id). We don’t need another exchange_id, since it is already implicitly given due to the foreign key on instrument‘s id attribute. For the actual time series data, we keep price_date as index, open_price, high_price, low_price, close_price, adj_close_price, and volume. Yet again, we also store the created_date and last_updated date.
4. Populating the SMD
With the SMD now having well-defined tables for all information that we want to store, it is about time to actually populate the database. This chapter will deal with the initialization process, i.e. writing a list of exchanges and data vendors to the database and selecting our universe of tradable assets to work with. Then, we will download historical price data for all of these instruments and write them to the database. Once this step is done, we already have a working SMD that we could use in the next steps of the Full Quant Tech Stack.
However, as the universe of tradable assets keeps changing everyday (new symbols get listed, old symbols get delisted) and new price data gets published daily, we are still not done yet. In the next chapter, we will upgrade the SMD with various update functionalities to keep our list of instruments up-to-date and always have the latest end-of-day price data available.
4.1. Optional: Story Time - Deciding on a Universe of Tradable Assets
Okay, this might get a bit lengthy, but it was still a very important lesson for me in the process of setting up my SMD. I learned quite a lot about data downloading / reading / transforming / writing as well as the importance of batch downloading and fetching exceptions.
So far, this guide has been relatively true to its sources. If you’re reading the aforementioned QuantStart article (please do) and the blog post on Reasonable Deviations (please do), you’ll find that both suggest a very similar approach to the database scheme. In fact, I tried to unify both approaches, simplifying at some places (e.g. the exchange table) and adding more detail at others (e.g. instrument table).
I didn’t want to limit my SMD to only securities of a specific index such as the S&P 500, thus I didn’t follow the QuantStart article anymore after the section on schema design. I liked Robert Andrew Martin‘s approach of downloading a .csv file of all securities listed on a certain exchange better. The NASDAQ’s website makes it very easy to download .csv files of stocks listed on NYSE, NASDAQ, and AMEX.
So far, so good. After downloading and reading the .csv file of all NYSE-listed securities, I had to perform some manual transforms to the data to get it from this …

… to a more readable structure that will be accepted by the database (note that at that time, I followed a slightly different schema for the SMD).

After writing this table to the database and adding Yahoo Finance as data vendor, I was finally able to query my SMD for every ticker, send a request to the Yahoo Finance API for historical price data, and write the result to the database. Version 1.0 of my SMD was up and running! I remember proudly sending screenshots of the 12 Mio. rows price table to some friends of mine ..
However, my initial joy did not last long, since after proceeding similarly with the .csv file of all NASDAQ-listed securities, my Yahoo Finance API calls kept crashing with some weird JSONDecodeError. I hadn’t changed anything on the code and the same logic that worked so well before now raised an error – frustrating. Luckily, I soon found a newly raised issue on the yfinance GitHub repository with my exact error and it seemed that the problem actually was on the Yahoo server end.
While I was waiting for the servers to accept API calls again, I compiled a list of the biggest and most representative stock exchanges for each major region of the world. I did not only want to focus on US equities and therefore my list of exchanges looked as follows:
| North America Exchanges | ||
|---|---|---|
|
XNGS |
Nasdaq Global Select |
United States |
|
XNYS |
New York Stock Exchange |
United States |
|
XTSE |
Toronto Stock Exchange |
Canada |
| South America Exchanges | ||
|---|---|---|
|
BVMF |
B3 S.A. - Brasil, Bolsa, Balcao |
Brazil |
| Europe Exchanges | ||
|---|---|---|
|
XAMS |
Euronext Amsterdam |
Netherlands |
|
XBRU |
Euronext Brussels |
Belgium |
|
XDUB |
Euronext Dublin |
Ireland |
|
XLIS |
Euronext Lisbon |
Portugal |
|
XPAR |
Euronext Paris |
France |
|
XLDN |
London Stock Exchange |
United Kingdom |
|
XNGM |
Nordic Growth Market |
Sweden |
|
XOSL |
Oslo Stock Exchange |
Norway |
|
XSWX |
SIX Swiss Exchange |
Switzerland |
| Germany Exchanges | ||
|---|---|---|
|
XBER |
Berlin Stock Exchange |
Germany |
|
XGAT |
Deutsche Boerse Tradegate |
Germany |
|
XDUS |
Dusseldorf Stock Exchange |
Germany |
|
XFRA |
Frankfurt Stock Exchange |
Germany |
|
XHAM |
Hamburg Stock Exchange |
Germany |
|
XHAN |
Hanover Stock Exchange |
Germany |
|
XMUN |
Munich Stock Exchange |
Germany |
|
XSTU |
Stuttgart Stock Exchange |
Germany |
|
XETR |
Xetra |
Germany |
| Middle East Exchanges | ||
|---|---|---|
|
XADS |
Abu Dhabi Securities Exchange |
United Arab Emirates |
|
XSAU |
Saudi Arabian Stock Exchange |
Saudi Arabia |
|
XTAE |
Tel Aviv Stock Exchange |
Israel |
| Africa Exchanges | ||
|---|---|---|
|
XJSE |
Johannesburg Stock Exchange |
South Africa |
| Asia Pacific Exchanges | ||
|---|---|---|
|
XASX |
Australian Securities Exchange |
Australia |
|
XBOM |
Bombay Stock Exchange |
India |
|
XHKG |
Hong Kong Stock Exchange |
Hong Kong |
|
XKRX |
Korea Exchange |
South Korea |
|
XNSE |
National Stock Exchange of India |
India |
|
XSHG |
Shanghai Stock Exchange |
China |
|
XSHE |
Shenzhen Stock Exchange |
China |
|
XTAI |
Taiwan Stock Exchange |
Taiwan |
|
XTKS |
Tokyo Stock Exchange |
Japan |
As you can probably already guess, this list of exchanges was not only thorough, but also a huge undertaking in getting ticker information for. The main problem that I faced was that not every exchange provided a handy, ready-to-download .csv file of their listed securities as the NASDAQ did. After some research, I stumbled across this site from Bloomberg which let me enter the MIC of the exchange and then returned a table of max. 5000 entries of listed securities that could be downloaded as a .csv file.
This small success was yet again overshadowed by another problem. Besides the actual ticker and company name, the .csv did not really provide any other corporate information that I wanted for my SMD. Thus, for every exchange, I read the .csv, kept only the tickers and wrote them to a list. I would then use these lists in the next step to query the Yahoo Finance API for corporate information on all the tickers to eventually fill the instrument table.
Querying Yahoo Finance for corporate information is straight-forward in theory:
import yfinance as yf yf.Ticker(ticker).info
The problem is that Yahoo Finance returns a dictionary of more than 150 key-value pairs for this call. Since I was only interested in a handful of those, I defined a constant list with my keys of interest (KOI) and filtered the returned dictionary for these pairs:
KOI = ['symbol', 'longName', 'sector', 'industry', 'country', 'website'] tmp = yf.Ticker(ticker).info data = {key: tmp[key] for key in KOI}
This approach worked well during the experimenting phase, and thus, I started the download of corporate information for my list of XNGS (NASDAQ Global Select) tickers (around 1500). Every iteration (request dictionary for current ticker and write to tmp variable, filter for KOI and write to data variable, append row to pandas dataframe) took around 6-7 seconds. After around 2 hours, my program froze (or at least the current iteration took more than 10 minutes), so I interrupted it. I probably encountered some timeout error on the Yahoo server side that was not caught in my try except block. It seemed that querying these large dictionaries for so many tickers at once was not an option.
Although a bit inconvenient (especially given the aggregated frustration from before), this problem made me familiarize myself with writing a batch download function that, as the name suggests, downloads the data in small batches rather than one big request. Once again, I took inspiration from Robert Andrew Martin and wrote the following two functions:
import time import pandas as pd import yfinance as yf from tqdm.auto import tqdm # to output nice progress bars for the data download
def get_info_batch(start_idx, end_idx, exchange, koi): """ Batch-wise download of key corporate information for a list of tickers :param start_idx: defines window of tickers within the passed list :param end_idx: defines window of tickers within the passed list :param exchange: list of tickers to get corporate information for :koi: which dictionary items to add to the return dataframe :return: dataframe that holds key corporate information of all tickers, list of tickers for which data could not be downloaded """ exchange_batch = pd.DataFrame() excepts = [] for ticker in tqdm(exchange[start_idx:end_idx]): try: tmp = yf.Ticker(ticker).info data = {key: tmp[key] for key in koi} exchange_batch = exchange_batch.append(data, ignore_index=True) except Exception as e: excepts.append(ticker) continue return exchange_batch, excepts
This is the actual download function that loops over a predetermined range (as specified by start_idx and end_idx) of elements in a given list of tickers (exchange) and queries Yahoo Finance for corporate information on each of these elements. It then filters the returned dictionary for the keys of interest (koi) and appends the data to the return dataframe (exchange_batch). Elements that raise an exception are written to a list (excepts) which is also returned for later inspection.
def get_corporate_info(exchange, batch_size, koi): """ Wrapper function to start a batch-wise download of corporate information for a list of tickers :param exchange: list of tickers to get corporate information for :koi: which dictionary items to add to the return dataframe :return: dataframe that holds key corporate information of all tickers, list of tickers for which data could not be downloaded """ n_batches = -(-len(exchange) // batch_size) exchange_df = pd.DataFrame() excepts = [] print("Downloading data in {} batches of size {}.".format(n_batches, batch_size)) for i in range(0, n_batches * batch_size, batch_size): exchange_batch, excepts_batch = get_info_batch(i, i + batch_size, exchange, koi) exchange_df = exchange_df.append(exchange_batch) excepts.append(excepts_batch) time.sleep(10) return exchange_df, excepts
This is the wrapper function which is actually called by the main program. It takes a list of tickers (exchange), a predetermined batch_size (e.g. 50) as well as the keys of interest (koi). First, the amount of batches (n_batches) is determined, then the get_info_batch() download function is called in a loop that goes over the ticker list in fixed intervals of length batch_size. The returns from the get_info_batch() function are appended to the exchange_df and excepts list. After each major batch, the function pauses for 10 seconds to allow for some ‘breathing’. I’m still not quite sure about the last part, but since I probably encountered some kind of timeout error before, I wanted to give the Yahoo Finance API some moments to rest before getting new requests from my IP address.
This approach seemed more promising and was also better designed, but I still ran into the same timeout issue as before. In a last desperate attempt, I decided to introduce another layer of batches by splitting the ticker list first into sub-arrays of roughly equal length but no more than 500 tickers max, then call the get_corporate_info() function and append its returned exchange_batch into a dataframe (exchange_df) outside of the function such that in case my program had to be interrupted again, at least some of the work had been already saved and I could restart the download from the current batch. I tried to visualize the process as such:
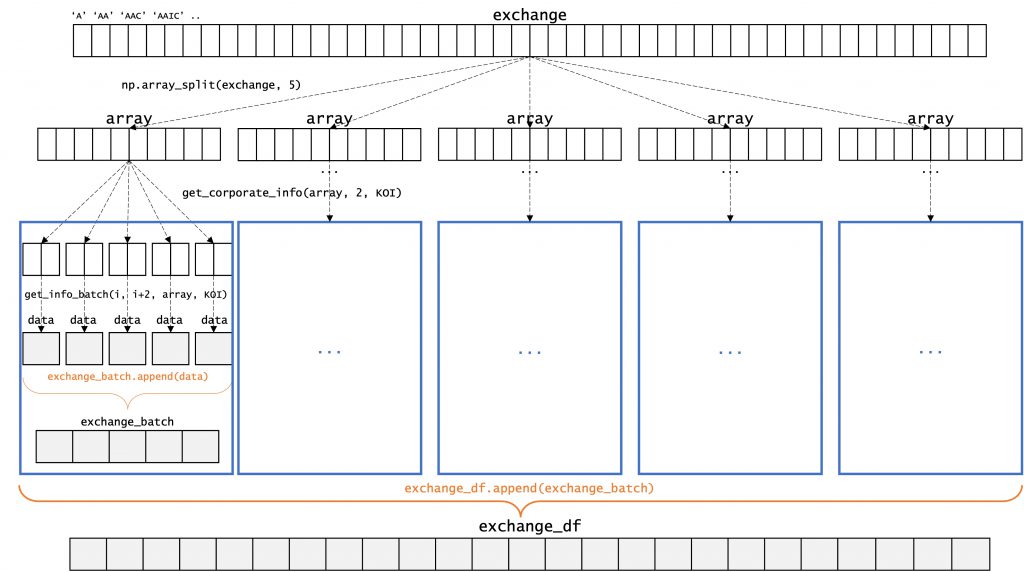
Finally, it worked! I didn’t even need my fallback option of restarting the download from some batch since splitting the exchange ticker list into several sub lists and then downloading the corporate information for the tickers in those sub lists in batches was enough to have a clean, constant download stream from Yahoo Finance. Downloading all of the ticker data for the XNGS (NASDAQ Global Select) now took around 3 hours and resulted, after some column renaming and adding the exchange_id, in a dataframe like this:

Now that my download process was finally running well, I knew that getting all of the corporate information for all tickers of all 35 exchanges would be as brute force as it could possibly get. But after training deep learning models all night for the Introduction to Deep Learning course that I took last summer term, I was already comfortable with letting my machine run for hours in the background. So, I started the download for the B3 S.A. – Brasil, Bolsa, Balcao stock exchange and laid back …
This whole story would not be complete with yet another issue. After another 2 hours, my program terminated and I eagerly inspected the resulting dataframe only to find it completely empty and the list of exceptions containing every single ticker. What happened? As it turns out, Yahoo Finance does not necessarily go by the same tickers as e.g. Bloomberg does. Whereas Bloomberg’s symbol for the company Fleury is simply FLRY3, Yahoo Finance lists it as FLRY3.SA. Therefore, every ticker in the list threw an exception. It was at this point that I finally threw in the towel and pushed the idea of an all-encompassing, international SMD way back into the future. I just didn’t have the nerve to yet again alter all the tickers to match Yahoo Finance’s schema, possibly for every exchange.
4.2. APIs for Data Retrieval
Although Yahoo Finance offers a vast universe of financial instruments, having to manually tweak tickers to suit Yahoo Finance’s schema as well as depending on an unofficial library (yfinance by Ran Aroussi) to interact with its API ultimately made me look for another, more streamlined data source.
During my research, I stumbled across this YouTube series by parttimelarry from Hacking the Markets. Larry is not only a funny and easy-to-listen-to guy, but he also explains very well how the different components of a full stack trading app play together. I highly recommend to check out his channel and website!
It was due to Larry’s videos that I came across the Alpaca Markets Trade API. Alpaca is an actual broker and thus does not only offer high quality data on stocks, ETFs and crypto, but also nicely integrates with popular strategy backtesting tools such as Backtrader and even offers an interface for paper and live trading. As I already noted down in this blog post, Alpaca seems to be a perfect companion all the way from data collection to live trading.
What ultimately convinced me to try out Alpaca is the fact that its API offers a function list_assets() that always returns an up-to-date JSON dictionary of active and tradable assets which makes it dead easy to keep up with new company / ETF listings and delistings. Otherwise, I would have had to handcraft a script that re-downloads static .csv files of exchange listings and compare those against the database over and over again – how tedious!
In a perfect world, we would just consider the Alpaca API from now on and discard Yahoo Finance for good. While that surely is a solution, it would have the following drawbacks:
- The Alpaca API does not provide additional corporate information such as sector or industry on its tickers
- The Alpaca API only provides a max. of 1000 trading days for historical prices and does not provide closing prices adjusted for corporate actions (adj. close)
Before you can actually use the Alpaca API, you’ll first have to register on the platform and open up a free individual account. After that’s done, switch from Live Trading to Paper Trading in the dashboard and generate your API keypair (private key & secret key). To use the API together with Python, make sure to pip install alpaca-trade-api in your project environment.
For any unclarities, refer to the official documentation.
4.3 Roadmap for Database Population
Going forward, I suggest to split the code into the following files:
|
init.ipynb |
Jupyter Notebook to go through the initial population cell by cell. |
|
config.py |
Python file to store constants such as URLs, API keys, etc. |
|
utils.py |
Python file to store function definitions. |
|
update.py |
Python file to regularly update the SMD (later via cronjobs). |
Which results in the backend directory to look something like this (with the data folder storing important interim results):
backend/ ├─ init.ipynb ├─ config.py ├─ utils.py ├─ update.py ├─ data/ │ ├─ ..
config.py
Throughout the initialization and later the updating steps, our program will need certain constant information such as the login details for the database connection, as well as the Alpaca API keys. Let’s store this information in the config.py file:
# Database DB_HOST = 'localhost' DB_USER = 'root' DB_PASSWORD = 'yourpassword' DB_DATABASE = 'securities_master' # Alpaca API API_URL = 'https://paper-api.alpaca.markets/' API_KEY = 'yourprivatekey' API_SECRET = 'yoursecretkey' # Yahoo Finance KOI = ['symbol', 'sector', 'industry', 'country', 'website'] # keys of interest BATCH_SIZE = 500 # max. number of tickers to be included in one batch
utils.py
I tried to generalize as much functionality for the initialization & updating process within the utils.py file. Throughout the init.ipynb and update.py file, we will call various functions from here. Let’s start with importing our config.py file and the packages needed for the functions:
import config as cf import pymysql.cursors import alpaca_trade_api as tradeapi import yfinance as yf import pandas as pd from pandas_datareader import data as pdr yf.pdr_override() # let pandas_datareader override yfinance for faster downloads (use pdr prefix instead of yf) from tqdm.auto import tqdm # to output nice progress bars for the data download import lxml.html as lh import requests import datetime import time import sys
Next, let’s write some simple functions to connect with our SMD and to retrieve the id of a specific exchange. We will need this functionality later when populating the instrument table.
def connect_db(): """ Connect to a MySQL database :return: connection object """ conn = pymysql.connect( host = cf.DB_HOST, user = cf.DB_USER, password = cf.DB_PASSWORD, database = cf.DB_DATABASE) print("|---------------| Successfully connected to {}. |---------------|".format(cf.DB_DATABASE)) return conn def get_exchange_id(acronym, conn): """ Given a MySQL database connection, query for the exchange id of a specified exchange :param acronym: acronym of exchange that id needs to be retrieved for :param conn: MySQL database connection :return: exchange id """ return pd.read_sql("SELECT id FROM exchange WHERE acronym = '{}'".format(acronym), conn).astype(int).iloc[0]['id']
Similarly, we’ll need some functions to interact with the Alpaca API. See their descriptions for an explanation of what they do:
def connect_api(): """ Connect to Alpaca API :return: api object """ api = tradeapi.REST(cf.API_KEY, cf.API_SECRET, cf.API_URL) print("|---------------| Successfully connected to Alpaca API. |---------------|") return api def populate_exchange_list(acronym, assets): """ Query the active and tradable asset universe for tickers of a specific exchange :param acronym: acronym of exchange that the assets should be queried for :param assets: list of asset objects to be queried :return: list of tickers listed on the given exchange """ exchange = [] for asset in assets: try: if asset.status == 'active' and asset.tradable and asset.exchange == acronym: exchange.append(asset.symbol) except Exception as e: continue return exchange def populate_exchange_df(acronym, assets, conn): """ Query the active and tradable asset universe for ticker data of a specific exchange :param acronym: acronym of exchange that the assets should be queried for :param assets: list of asset objects to be queried :param conn: MySQL database connection :return: dataframe of tickers with their corresponding exchange_id, symbol, and name of the given exchange """ exchange_df = pd.DataFrame(columns = ['exchange_id', 'ticker', 'name']) for asset in assets: try: if asset.status == 'active' and asset.tradable and asset.exchange == acronym: tmp = {'exchange_id' : get_exchange_id(acronym, conn), 'ticker' : asset.symbol, 'name' : asset.name} exchange_df = exchange_df.append(tmp, ignore_index = True) except Exception as e: continue return exchange_df
init.ipynb
4.3.1. Imports
We need to import the config.py and utils.py files, as well as some other packages:
import config as cf import utils as ut import numpy as np import pandas as pd import datetime import pickle
4.3.2. Connections
Then, we need to connect to our SMD as well as the Alpaca API. Be aware that the MySQL server has to be running already (mysql.server start)! The package pymysql allows us to save the connection in a variable and create a cursor object to execute SQL queries via Python. If we want to make lasting changes to the database, we need to call conn.commit(). To close the connection, we call cursor.close() and conn.close().
# Connect to DB conn = ut.connect_db() cursor = conn.cursor() # Connect to Alpaca API api = ut.connect_api()
4.3.3. Write Exchanges to SMD
In the first step of our initial database population, we’ll add all exchanges to our SMD that Alpaca provides data for. To find out which ones they are, we can simply call:
exchanges = {asset.exchange for asset in assets} print(exchanges)
{'AMEX', 'OTC', 'NYSE', 'ARCA', 'BATS', 'NASDAQ'} I decided to drop the OTC market, since only a handful of active and tradable assets are actually listed on here which leaves us with the following exchanges (get MIC Codes & Acronyms here):
| North America Exchanges | ||
|---|---|---|
|
XNAS |
NASDAQ |
Nasdaq - All Markets |
|
XNYS |
NYSE |
New York Stock Exchange |
|
XASE |
AMEX |
NYSE American |
|
ARCX |
ARCA |
NYSE Arca |
|
BATS |
BATS |
Bats Global Markets |
Now, we can add the exchanges to the SMD simply by calling:
sql = """ INSERT INTO exchange (mic_code, acronym, name, region, country, city, currency) VALUES ('XNAS', 'NASDAQ', 'Nasdaq - All Markets', 'North America', 'United States', 'New York', 'USD'), ('XNYS', 'NYSE', 'New York Stock Exchange', 'North America', 'United States', 'New York', 'USD'), ('XASE', 'AMEX', 'NYSE American', 'North America', 'United States', 'New York', 'USD'), ('ARCX', 'ARCA', 'NYSE Arca', 'North America', 'United States', 'New York', 'USD'), ('BATS', 'BATS', 'Bats Global Markets', 'North America', 'United States', 'Chicago', 'USD');""" cursor.execute(sql) conn.commit()
A quick check via MySQL Workbench (SELECT * FROM exchange;) shows that everything worked well and we just successfully added the first data tuples to our SMD!

4.3.4. Write Instruments to SMD
As convenient as the Alpaca API is, it unfortunately does not provide a lot of meta information on its tradable assets. Besides the ticker and name, we don’t really get much more corporate information on the financial instrument. You’ll notice that the database schema for the instrument table as defined in the very beginning, asks for more information than just the ticker and name. It would be very convenient to additionally store the sector and industry, as well as the country and website of each asset such that we can filter the instruments in a more detailed fashion. For instance, we could later on try to scan for supertrends, i.e. whole sectors or industries showing momentum effects or we could try to access an interesting company’s website for further webscraping.
This is where the Yahoo Finance API comes in. I went into much detail about getting corporate information via Yahoo Finance in the optional read 4.1. Story Time – Deciding on a Universe of Tradable Assets, so if not done already you might want to go back and skim through the chapter after all. Basically though, we will write some functions to query Yahoo Finance for a list of tickers of an exchange, filter the returned dictionaries for our keys of interest (sector, industry, country, website) and write the result into an exchange_info dataframe. We will then combine the exchange_alpaca dataframe of tickers and names that we got from the Alpaca API with the exchange_info dataframe from Yahoo Finance via an outer join on the ticker, leaving us with an exchange_df dataframe that contains all active and tradable tickers of that exchange that Alpaca provides historical pricing data for, with most of them being refined with additional, corporate information from Yahoo Finance. Easy-peasy right?
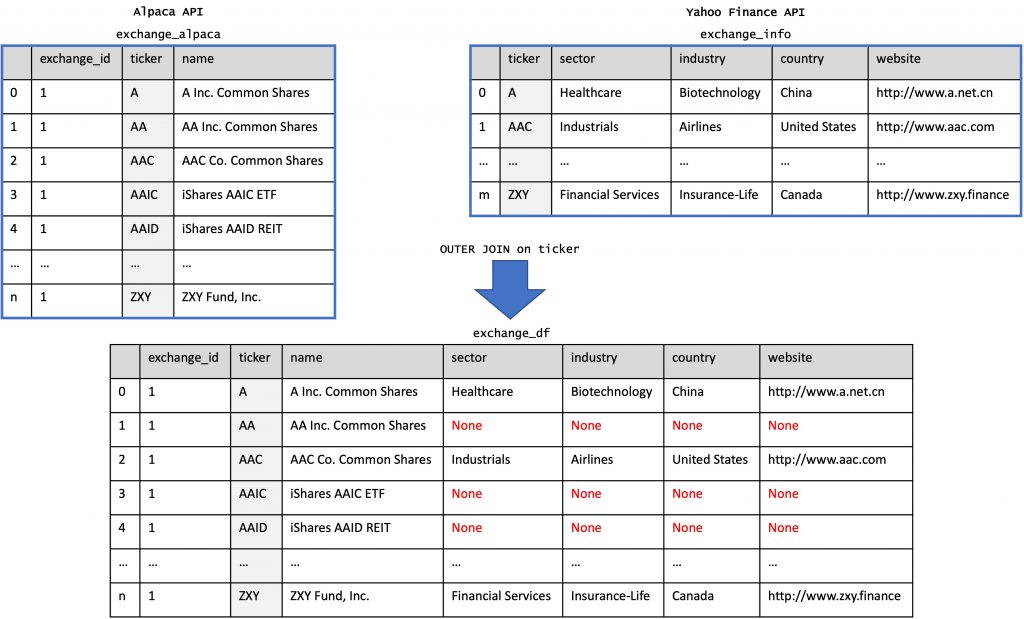
Back in the utils.py file, let us write the functions needed for the Yahoo Finance API calls. To understand the logic behind the get_corporate_info() and get_info_batch() batch-downloading functions, feel free to go back to the optional read.
def determine_splits(exchange, batch_size): """ Determines the amount of splits for a list, given a batch_size :param exchange: list for which splits should be determined :param batch_size: max. amount of tickers to be included in one batch :return: amount of splits """ return -(-len(exchange) // batch_size) def get_corporate_info(exchange, batch_size, koi): """ Wrapper function to start a batch-wise download of corporate information for a list of tickers :param exchange: list of tickers to get corporate information for :param batch_size: max. amount of tickers to be included in one batch :koi: which dictionary items to add to the return dataframe :return: dataframe that holds key corporate information of all tickers """ n_batches = determine_splits(exchange, batch_size) exchange_df = pd.DataFrame() print("Downloading data in {} batches of size {}.".format(n_batches, batch_size)) for i in range(0, n_batches * batch_size, batch_size): exchange_batch = get_info_batch(i, i + batch_size, exchange, koi) exchange_df = exchange_df.append(exchange_batch) time.sleep(10) return exchange_df def get_info_batch(start_idx, end_idx, exchange, koi): """ Batch-wise download of key corporate information for a list of tickers :param start_idx: defines window of tickers within the passed list :param end_idx: defines window of tickers within the passed list :param exchange: list of tickers to get corporate information for :koi: which dictionary items to add to the return dataframe :return: dataframe that holds key corporate information of all tickers """ exchange_batch = pd.DataFrame() for ticker in tqdm(exchange[start_idx:end_idx]): try: tmp = yf.Ticker(ticker).info data = {key: tmp[key] for key in koi} exchange_batch = exchange_batch.append(data, ignore_index = True) except Exception as e: continue return exchange_batch
Before we can start with populating the instrument table, we first have to get our universe of assets from Alpaca via my favorite function:
assets = api.list_assets()
Then, we can put our populate_exchange_list() function to use and store the tickers of all active and tradable assets by exchange:
nasdaq = ut.populate_exchange_list('NASDAQ', assets) nyse = ut.populate_exchange_list('NYSE', assets) amex = ut.populate_exchange_list('AMEX', assets) arca = ut.populate_exchange_list('ARCA', assets) bats = ut.populate_exchange_list('BATS', assets)
Lastly, we need to cast these lists of tickers to a format that is accepted by Yahoo Finance. As I’ve already had to learn the hard way (see optional read), tickers are not completely unambiguous and different data vendors have different semantics for them. For instance, while Alpaca handles different tranches via a dot followed by the tranche identifier (e.g. .A), Yahoo Finance does so via a hyphen (e.g. -A). Thus, if we do not account for those peculiarities, we will get much less data from Yahoo Finance. Let’s quickly write two functions, one to cast the tickers to Yahoo Finance format, and the other to cast them back to Alpaca format:
def cast_to_alpaca(exchange): """ Cast tickers from Yahoo Finance format to Alpaca format :param exchange: list of tickers to be casted :return: list of tickers in Alpaca format """ for i in range(0, len(exchange)): # Strings are immutable, we therefore need new assignment exchange[i] = exchange[i].replace('-UN', '.U') exchange[i] = exchange[i].replace('-', '.') return exchange def cast_to_yf(exchange): """ Cast tickers from Alpaca format to Yahoo Finance format :param exchange: list of tickers to be casted :return: list of tickers in Yahoo Finance format """ for i in range(0, len(exchange)): # Strings are immutable, we therefore need new assignment exchange[i] = exchange[i].replace('.U', '-UN') exchange[i] = exchange[i].replace('.', '-') return exchange
Let’s use these functions to update our ticker lists to Yahoo Finance format:
nasdaq = sorted(ut.cast_to_yf(nasdaq)) nyse = sorted(ut.cast_to_yf(nyse)) amex = sorted(ut.cast_to_yf(amex)) arca = sorted(ut.cast_to_yf(arca)) bats = sorted(ut.cast_to_yf(bats))
Exemplary Process on AMEX
With all of the preparations being done, the following will demonstrate in detail how to populate the AMEX exchange dataframe.
From the init.ipynb file, call the populate_exchange_df() function from utils.py and pass it the acronym AMEX, the Alpaca stock universe assets, as well as the connection object conn (needed to get the correct exchange_id).
amex_alpaca = ut.populate_exchange_df('AMEX', assets, conn) amex_alpaca
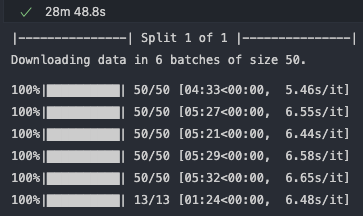
Then, call the following cell to start the download process of corporate information from Yahoo Finance for the AMEX tickers. In order not to overload the Yahoo server with too many requests at once, we first split the list of tickers into several sub-arrays of roughly the same size (max. of 500). For each of those sub-arrays, we then call the get_corporate_info() function which then calls the get_info_batch() function to download corporate information from Yahoo Finance in batches of 50 for the current sub-array. All of the resulting sub-dataframes are then appended to the amex_info dataframe.
splits = ut.determine_splits(amex, cf.BATCH_SIZE) split_arr = np.array_split(amex, splits) amex_info = pd.DataFrame() count = 1 for array in split_arr: print("|---------------| Split {} of {} |---------------|".format(count, splits)) tmp = ut.get_corporate_info(array, 50, cf.KOI) amex_info = amex_info.append(tmp) count += 1
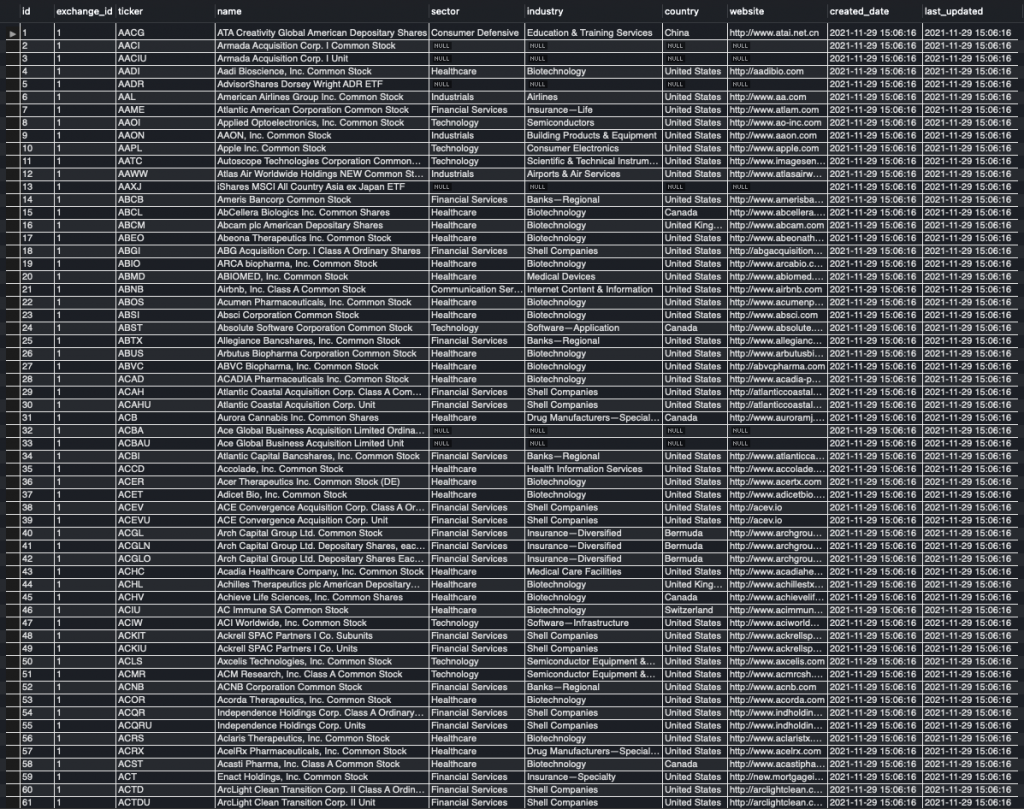
After the download is done, let’s view the resulting amex_info dataframe:
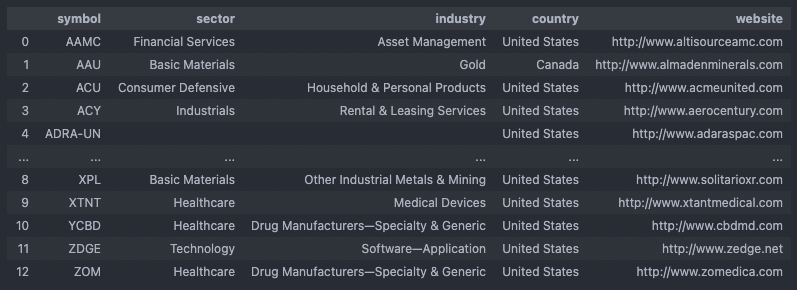
Everything seems to have worked, although some tickers are obviously missing. These tickers must have thrown an exception when trying to query the API for them and have thus been dropped. But since we will do an outer join later with the amex_alpaca dataframe anyways, we will not lose these tickers – just don’t have additional information for them. Next, let’s re-cast the tickers to Alpaca format and rename the column symbol to ticker.
tmp = ut.cast_to_alpaca(amex_info['symbol'].tolist()) amex_info.drop('symbol', axis = 1, inplace = True) amex_info.insert(0, 'ticker', tmp)
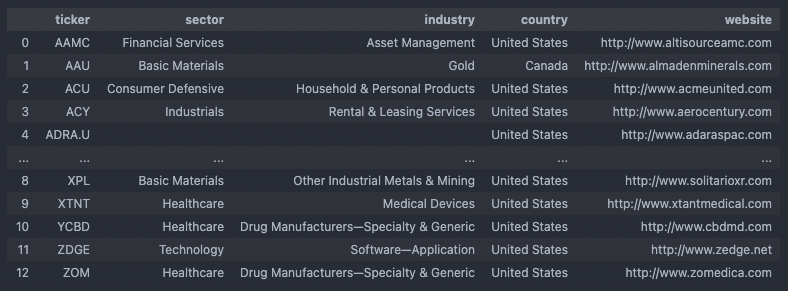
Lastly, we’ll join the two dataframes amex_alpaca and amex_info on ticker and sort the resulting amex_df dataframe.
amex_df = pd.merge(amex_alpaca, amex_info, on = 'ticker', how = 'outer') amex_df = amex_df.sort_values(by = ['ticker'])
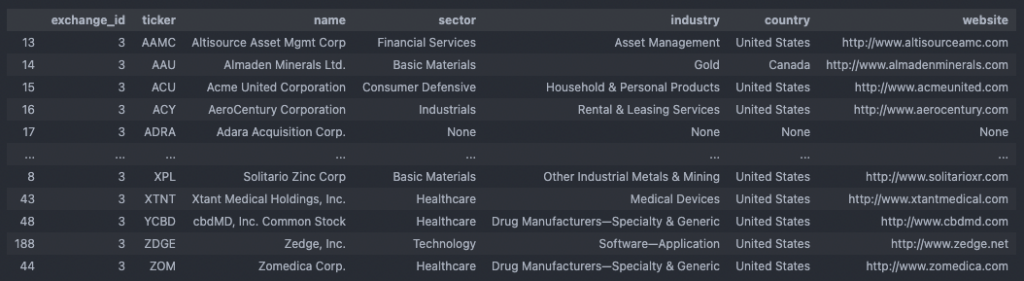
We can now save our progress by writing the dataframe to a .csv file. Downloading all the ticker data for every exchange takes a lot of time, so you might want to distribute the process over several days. Before actually adding the data to the SMD, we will read the .csv files back in again.
amex_df.to_csv('data/AMEX.csv')
Rinse & Repeat with the other exchanges
Repeat the process described above for AMEX for every other exchange. Altogether, the corporate information downloads from Yahoo Finance took around pretty much exactly 20 hours for me.
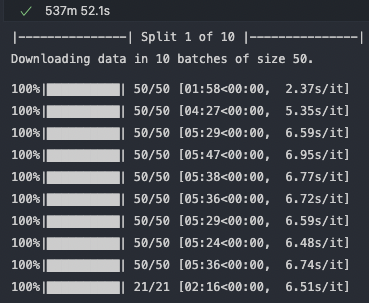
In exchange for that, I got additional information on around 90% of AMEX and NYSE tickers, as well as 75% of NASDAQ tickers, which, in my opinion, was well worth the effort. Unfortunately, for ARCA and BATS, I only got additional information on less than 1% of tickers. My educated guess is that Yahoo Finance does not hold any corporate information on ETFs and other non-common-stock instruments that are mainly listed in these two exchanges.
Actually Writing to the SMD
Once you’ve got all your .csv files, it is about time to read them back in and finally add the contained information to the SMD. Note that when reading from .csv, we need to drop the Unnamed: 0 column, as well as replace NaN values with None for MySQL to work with:
amex_df = pd.read_csv('data/AMEX.csv') amex_df = amex_df.loc[:, amex_df.columns != 'Unnamed: 0'] amex_df = amex_df.replace({np.nan: None})
After reading all .csv files back in and post-processing them as described above, we add them to a dictionary …
exchanges = { 'NASDAQ': nasdaq_df, 'NYSE': nyse_df, 'AMEX': amex_df, 'ARCA': arca_df, 'BATS': bats_df, }
… and then simply iterate over every row of every exchange to add it to the database. This process might seem daunting at first, but it actually takes less than a second to execute! By replacing all NaN cells with None before, we made sure that each row can be inserted into the table, even if it does not have complete information for every cell.
for key, exchange in exchanges.items(): for row in exchange.itertuples(index = False): cursor.execute("INSERT INTO instrument (exchange_id, ticker, name, sector, industry, country, website) VALUES (%s, %s, %s, %s, %s, %s, %s)", row) conn.commit()
Now, we have more than 10,000 financial instruments (equities and ETFs) from five different US exchanges in our database and for most of them, we even got additional information such as the sector and industry, country and website.
Additionally, if we ever need to setup the SMD from scratch again, we already have the .csv files which let us initialize the database within minutes!
Great success!
4.3.5. Write Vendor to SMD
We will be using a combination of the Yahoo Finance and Alpaca APIs for populating the price table. Let’s quickly add these two manually to the vendor table:
# Yahoo Finance sql = "INSERT INTO vendor (name, website) VALUES ('Yahoo Finance', 'https://finance.yahoo.com/')" cursor.execute(sql) conn.commit() # Alpaca sql = "INSERT INTO vendor (name, website) VALUES ('Alpaca', 'https://alpaca.markets/')" cursor.execute(sql) conn.commit()

4.3.6. Write Prices to SMD
We have finally arrived at the last step of the initial database population! All that’s left to do, is to download as much historical pricing data as possible for every ticker in the instruments table. As already foreshadowed before, we will yet again combine the Yahoo Finance and Alpaca APIs, trying to download as much data for as many tickers as possible via Yahoo Finance and then fill in the blanks with data from Alpaca. The id of the vendor table will help us in distinguishing between the two data sources.
To make sure not to accidentally download intraday pricing data for the current day, we will download historical data only up to yesterday’s date:
today = datetime.date.today() yesterday = str(today - datetime.timedelta(days = 1))
Before we can start, we need to add some more functions to our utils.py file. First, let’s write some quick functions to retrieve a list of all tickers of a specific exchange, as well as the vendor id from the database:
def get_exchange_tickers(acronym, conn): """ Given a MySQL database connection, query for the tickers of a specified exchange :param acronym: acronym of exchange that tickers needs to be retrieved for :param conn: MySQL database connection :return: dataframe of tickers with their corresponding ids """ exchange_id = get_exchange_id(acronym, conn) return pd.read_sql("SELECT ticker, id FROM instrument WHERE exchange_id = '{}'".format(exchange_id), conn) def get_vendor_id(name, conn): """ Given a MySQL database connection, query for the vendor id of a specified vendor :param name: name of vendor that id needs to be retrieved for :param conn: MySQL database connection :return: vendor id """ return pd.read_sql("SELECT id FROM vendor WHERE name = '{}'".format(name), conn).astype(int).iloc[0]['id']
Next is the function for querying the Yahoo Finance API for a set of tickers and write their pricing history directly to the database. We will keep track of those tickers for which Yahoo Finance either returns an empty dataframe or an exception such that we can later query the Alpaca API for those instruments:
def write_historical_prices_yf(tickers, conn, cursor, start_date, end_date): """ Retrieves historical prices for a set of tickers from Yahoo Finance and writes them directly to the database :param tickers: list of tickers for which prices should be written :param conn: MySQL database connection :param cursor: MySQL database cursor for query execution :param start_date: earliest price date :param end_date: latest price date :return: list of tickers that no data could be retrieved for, casted to Alpaca format """ ticker_index = dict(tickers.to_dict('split')['data']) ticker_list = cast_to_yf(list(ticker_index.keys())) vendor = get_vendor_id('Yahoo Finance', conn) excepts = [] for ticker in tqdm(ticker_list): try: tmp = pdr.get_data_yahoo(ticker, start = start_date, end = end_date, progress = False) if tmp.empty: excepts.append(ticker) # tickers that no exception was raised but no data was found continue for row in tmp.itertuples(): values = [vendor, ticker_index[ticker]] + list(row) sql = "INSERT INTO price (vendor_id, ticker_id, price_date, open_price, high_price, low_price, close_price, adj_close_price, volume) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(sql, tuple(values)) except Exception as e: excepts.append(ticker) # tickers for which an exception was thrown continue conn.commit() print("|---------------| Data successfully written to database. |---------------|") return cast_to_alpaca(excepts)
Since we will be calling the write_historical_prices_yf() function batch-wise, similarly to when we were querying Yahoo Finance for corporate information on the tickers, the resulting excepts list will consist of several lists of excepts itself. We therefore need a function to ‘flatten’ the list such that we can pass it to the Alpaca API:
def flatten_exceptions(excepts): """ Flattens a list with 2 levels. :param excepts: list of lists to be flattened :return: flattened list """ return [[item for sublist in excepts for item in sublist]][0]
Lastly, to get pricing data for the Yahoo Finance excepts, we’ll write a very similar function that queries the Alpaca API and writes the data directly to the SMD. Since we are querying for the maximum amount of data, it doesn’t really matter which start and end dates we’re passing to the function. In a later chapter, I will talk a bit more about Alpaca’s peculiarities for start and end dates, but for now, it suffices to query for the whole history (limit = 1000) of prices and manually dropping the row for the current date.
def write_historical_prices_alpaca(tickers, api, conn, cursor, start_date, end_date): """ Retrieves historical prices for a set of tickers from Alpaca and writes them directly to the database :param tickers: list of tickers for which prices should be written :param api: Alpaca api object :param conn: MySQL database connection :param cursor: MySQL database cursor for query execution :param start_date: earliest price date :param end_date: latest price date """ ticker_index = dict(tickers.to_dict('split')['data']) ticker_list = list(ticker_index.keys()) vendor = get_vendor_id('Alpaca', conn) for ticker in tqdm(ticker_list): try: tmp = api.get_barset(ticker, 'day', limit = 1000, start = start_date, end = end_date).df tmp.drop(tmp.tail(1).index, inplace = True) # drop row for 'today' as long as end_date is not working for row in tmp.itertuples(): values = [vendor, ticker_index[ticker]] + list(row) sql = "INSERT INTO price (vendor_id, ticker_id, price_date, open_price, high_price, low_price, close_price, volume) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(sql, tuple(values)) except Exception as e: continue conn.commit() print("|---------------| Data successfully written to database. |---------------|") return
To get started, let’s read in all tickers from our database by exchange:
nasdaq_tickers = ut.get_exchange_tickers('NASDAQ', conn) nyse_tickers = ut.get_exchange_tickers('NYSE', conn) amex_tickers = ut.get_exchange_tickers('AMEX', conn) arca_tickers = ut.get_exchange_tickers('ARCA', conn) bats_tickers = ut.get_exchange_tickers('BATS', conn)
Exemplary Process on AMEX
As before, I will go through the price population process in detail for the AMEX exchange.
First, we split up the dataframe of AMEX tickers (ticker and corresponding id) into several sub-dataframes of roughly equal length (max. 500) and store those in a list (amex_tickers_list) to iterate over. For each of those sub-dataframes, we then call the write_historical_prices_yf() function to download price data from Yahoo Finance for the current sub-dataframe and store its list of excepts in a temporary variable. Over the course of the loop, we append this temporary list of excepts to the amex_excepts list which, at the end, is flattened and then pickled to a .txt file in case we need to read in the excepts again sometime in the future.
splits = ut.determine_splits(amex_tickers['ticker'].to_list(), cf.BATCH_SIZE) amex_tickers_list = [amex_tickers.loc[i : i + cf.BATCH_SIZE - 1, : ] for i in range(0, len(amex_tickers), cf.BATCH_SIZE)] amex_excepts = [] count = 1 for batch in amex_tickers_list: print("|---------------| Split {} of {} |---------------|".format(count, splits)) tmp = ut.write_historical_prices_yf(batch, conn, cursor, None, yesterday) amex_excepts.append(tmp) count += 1 pickle.dump(ut.flatten_exceptions(amex_excepts), open("data/AMEX.txt", "wb"))

You might get some failed download warnings as I did above but don’t worry – our amex_excepts list keeps track of those tickers such that we can query the Alpaca API for their price history later.
Depending on whether you had to stop your coding session after the data download, you might want to read the exceptions back in again via:
amex_excepts = pickle.load(open("data/AMEX.txt", "rb"))
['ADRA.U', 'ARMP', 'BTTR', 'CEI', 'GLTA.U', 'PHGE.U', 'VHAQ.RT', 'VHAQ.U']
We iterate over this list of tickers to populate the amex_alpaca dataframe with their tickers and ids and finally call the write_historical_prices_alpaca() function to download their price history from the Alpaca API.
amex_alpaca = pd.DataFrame() for ticker in amex_excepts: amex_alpaca = amex_alpaca.append(amex_tickers[amex_tickers['ticker'] == ticker]) ut.write_historical_prices_alpaca(amex_alpaca, api, conn, cursor, None, yesterday)

Rinse & Repeat with the other exchanges
Repeat the process described above for every other exchange. Luckily, populating the prices takes just a fraction of the time needed for downloading corporate information. For me, it took a bit more than 3 hours in total.
As a result, our price table now holds close to 30 Mio. rows of historical price data for every ticker in the database! For 97% of those tickers, pricing history goes back as far as possible thanks to Yahoo Finance’s insane data pool, and for the remaining 3%, we got at least four years of data from the Alpaca API.
With that, we finally have a first, working version of a Securities Master Database! Hooray!
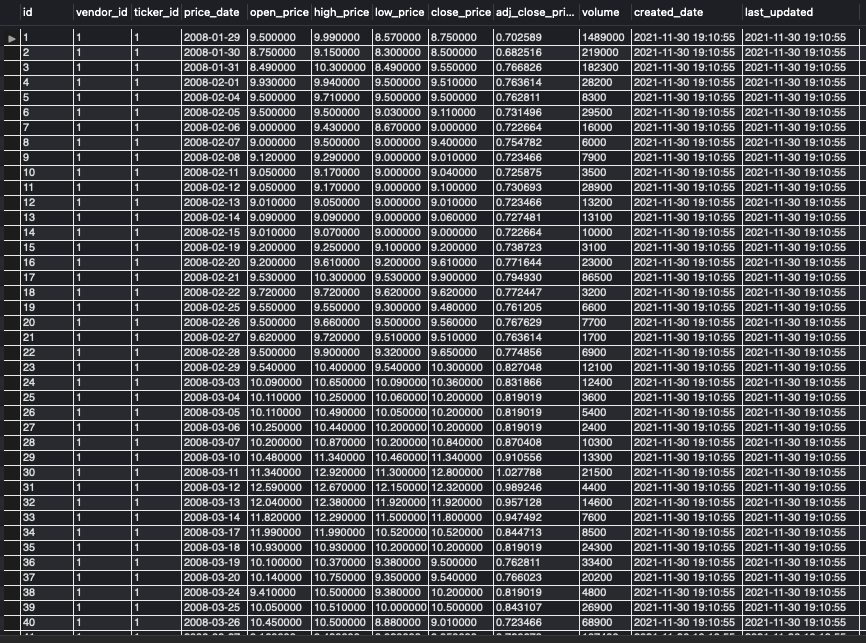
5. Updating the SMD
With all of the above taken care of, there is only one thing left to implement: an update mechanism. Companies get IPO-ed regularly, and new, exiting ETFs get launched all the time. But the opposite is also true, with tickers getting delisted, either for insolvency or M&A activity. And as we’ve recently seen with Facebook’s rebranding to Meta, even companies’ names are not safe from change. Also, given that we have around 10,000 tickers in our instrument table, we can expect to get 10,000 rows of new price data every single weekday!
Since we want our SMD to be an always-up-to date data source, we need to make sure to update it regularly. For now, we’ll write an update.py script that we need to execute manually to check for newly listed tickers, get corporate information for them, load their entire price history, preferably from Yahoo Finance, and add new price rows for the existing tickers. In the future, I’m planning on automating this process via a cronjob – but it only makes sense to do so once the database is not hosted locally on my Mac anymore, but either on a cloud service such as AWS, Linode or Digital Ocean, or even better on a personal, always-on Raspberry Pi Server.
I’m also thinking about writing a cleanup.py script to run on weekends that identifies and deletes data for those tickers that have been delisted or are nothing more than SPACs, and alters instrument records where name changes have occurred. But since this functionality is more icing on the cake than anything else, I’ll skip it for now and add it to the ever-expanding backlog of possible SMD upgrades (I’m looking at you, Chapter 7. Open Issues).
Before we actually get going, let’s create an update.py file, import what we’ll need and connect to the endpoints:
# Imports import config as cf import utils as ut import numpy as np import pandas as pd pd.options.mode.chained_assignment = None # default = 'warn' import time # optional: if you want to use some time.sleep() statements for better output readability # Connections conn = ut.connect_db() cursor = conn.cursor() api = ut.connect_api()
5.1. New Instruments
In this first part of the update.py script, we’ll check for tickers that have been newly added to the Alpaca API and try to download additional corporate information from Yahoo Finance for as many as possible of them. After adding these to the instrument table, we’ll download their entire price history via Yahoo Finance, collect those tickers that return an empty dataframe or throw an exception and query the Alpaca API for them, just as when we were initializing the SMD in the first place.
5.1.1. Adding New Instruments
As before, let’s put as much functionality as possible into some utils.py functions. First, we need to query the SMD for every contained ticker and return the result as a list (get_all_tickers()). Second, we need to compare those tickers against the current universe of active and tradable assets from Alpaca, identify the tickers that we don’t already have in the database and write them with their corresponding exchange and name into a dataframe for further usage (get_new_tickers()). This function also makes sure that we only consider new instruments from exchanges that are already in our database (remember, we left out the OTC market for instance), and hence needs the get_all_exchanges() function. Finally, we write another function get_yesterday() that gives back yesterday’s date in datetime format, or, if yesterday would be either Sunday or Saturday where no new prices get published anyways, the date of the last past weekday (= Friday).
def get_all_exchanges(conn): """ Queries the database for every existing exchange and returns their acronym as a list :param conn: MySQL database connection :return: list of all exchange acronyms """ return pd.read_sql('SELECT acronym FROM exchange', conn)['acronym'].to_list() def get_all_tickers(conn): """ Queries the database for every existing ticker and returns them as a list :param conn: MySQL database connection :return: list of all tickers """ return pd.read_sql('SELECT ticker FROM instrument', conn)['ticker'].to_list() def get_new_tickers(assets, tickers, conn): """ Compares an asset universe from the Alpaca API against a list of tickers and returns a dataframe of new tickers to be added to the database :param assets: list of asset objects to be queried :param tickers: list of tickers to compare against :param conn: MySQL database connection :return: dataframe of all newly identified tickers with their corresponding exchange, symbol and name """ new_tickers_df = pd.DataFrame() for asset in assets: try: if asset.status == 'active' and asset.tradable and asset.exchange in get_all_exchanges(conn) and asset.symbol not in tickers: data = [] data.append([asset.exchange, asset.symbol, asset.name]) tmp = pd.DataFrame(data, columns = ['exchange_id', 'ticker', 'name']) new_tickers_df = new_tickers_df.append(tmp, ignore_index = True) print('Identified a new instrument: {}, {} ({})'.format(asset.symbol, asset.name, asset.exchange)) except Exception as e: continue return new_tickers_df def get_yesterday(): """ Determines 'yesterday', i.e. the last past weekday to today's date :return: 'yesterday' in datetime format """ today = datetime.date.today() yesterday = today - datetime.timedelta(days = 1) if yesterday.weekday() == 5: # yesterday was Saturday -> go back to Friday yesterday -= datetime.timedelta(days = 1) elif yesterday.weekday() == 6: # yesterday was Sunday -> go back to Friday yesterday -= datetime.timedelta(days = 2) return yesterday
With these new functions, we can start off the update.py script as follows:
assets = api.list_assets() tickers = ut.get_all_tickers(conn) yesterday = str(ut.get_yesterday()) new_tickers_alpaca = ut.get_new_tickers(assets, tickers, conn)
You could imagine the new_tickers_alpaca dataframe to look something like this, given that new instruments have been identified:
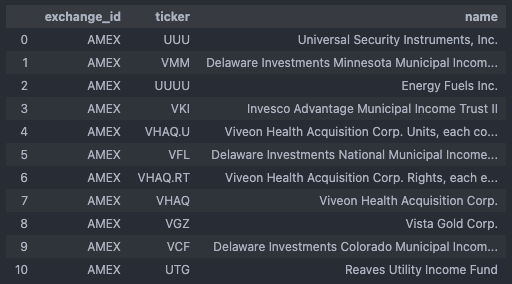
If no new tickers can be identified, our SMD is already up-to-date and we can directly skip to the next sub-chapter. If not, we need to transform the new_tickers_alpaca dataframe a bit and later merge it with the new_tickers_info dataframe that holds additional corporate information from Yahoo Finance.
So far, the exchange_id column of the new_tickers_alpaca dataframe holds the acronyms of the new instruments’ exchanges. Let’s switch those out with the correct ids from the SMD:
if new_tickers_alpaca.empty: new_tickers = [] # no new tickers else: exchanges = new_tickers_alpaca['exchange_id'].to_list() tmp = [] for exchange in exchanges: tmp.append(ut.get_exchange_id(exchange, conn)) new_tickers_alpaca.drop('exchange_id', axis = 1, inplace = True) new_tickers_alpaca.insert(0, 'exchange_id', tmp)

The remaining process is now very similar to the initial price population. First, cast all the tickers of the new_tickers_alpaca dataframe to Yahoo Finance format, then split this list into several sublists (probably not needed since there will hardly be more than 500 newly identified tickers) and iterate over each of them to download corporate information from Yahoo Finance. Then, transform the resulting new_tickers_info dataframe to suit the database schema, recast the tickers to Alpaca format and merge it with the new_tickers_alpaca dataframe. After replacing all NaN values with None, we can add the new instruments to the database:
# still within the else clause new_tickers = sorted(ut.cast_to_yf(new_tickers_alpaca['ticker'].to_list())) # cast tickers to YF format # Starting Corporate Information download from Yahoo Finance splits = ut.determine_splits(new_tickers, cf.BATCH_SIZE) split_arr = np.array_split(new_tickers, splits) new_tickers_info = pd.DataFrame() count = 1 for array in split_arr: print("|---------------| Split {} of {} |---------------|".format(count, splits)) tmp = ut.get_corporate_info(array, 25, cf.KOI) new_tickers_info = new_tickers_info.append(tmp) count += 1 new_tickers = ut.cast_to_alpaca(new_tickers) tmp = ut.cast_to_alpaca(new_tickers_info['symbol'].tolist()) # cast tickers back to Alpaca format new_tickers_info.drop('symbol', axis = 1, inplace = True) new_tickers_info.insert(0, 'ticker', tmp) new_tickers_df = pd.merge(new_tickers_alpaca, new_tickers_info, on = 'ticker', how = 'outer') new_tickers_df = new_tickers_df.sort_values(by = ['ticker']) new_tickers_df = new_tickers_df.replace({np.nan: None}) # Writing to database for row in new_tickers_df.itertuples(index = False): cursor.execute("INSERT INTO instrument (exchange_id, ticker, name, sector, industry, country, website) VALUES (%s, %s, %s, %s, %s, %s, %s)", row) conn.commit()
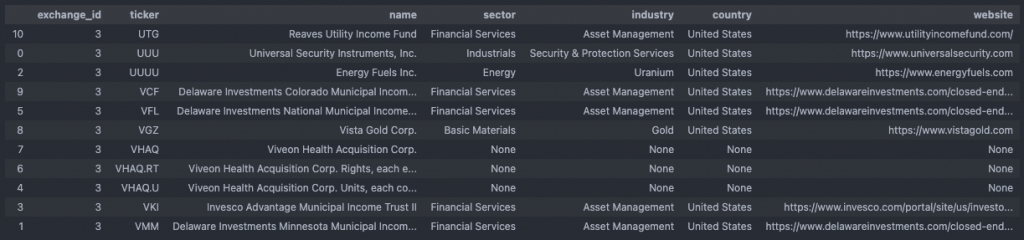
In my case, updating the SMD six days after its initial population already yielded 42 new instruments for 16 of which the Yahoo Finance detour was able to pull additional corporate information. Notice how the ids seamlessly increased thanks to the AUTO_INCREMENT constraint in the table schema. Also, the created_date now allows us to easily select those new entries, if need be (SELECT * FROM instrument WHERE created_date > ‘2021-12-05 00:00:00’;).
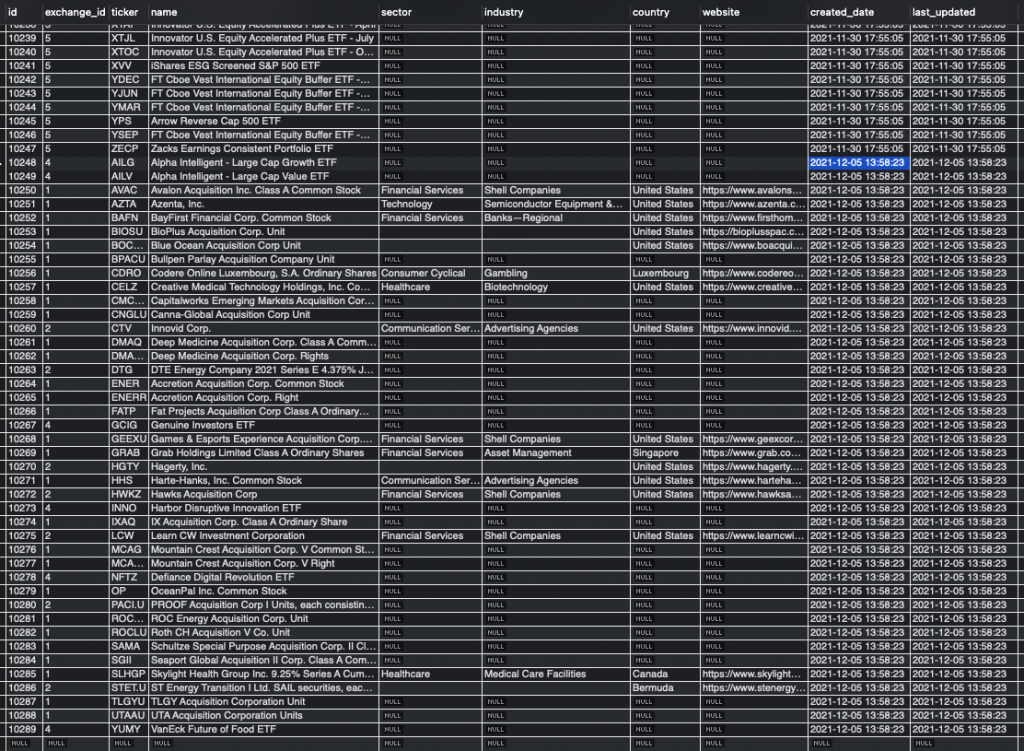
5.1.2. Downloading Price Histories
Downloading the price histories of the newly added tickers is exactly the same as during the initialization phase, we just need to read in these new tickers with their corresponding ids from the database first.
def get_tickers_from_list(tickers, conn): """ Queries the database for a given list of tickers and returns a dataframe of their symbols and ids :param tickers: list of tickers to be queried for :conn: MySQL database connection :return: dataframe of tickers and ids """ ticker_df = pd.DataFrame() for ticker in tickers: try: tmp = pd.read_sql("SELECT ticker, id FROM instrument WHERE ticker = '{}'".format(ticker), conn) ticker_df = ticker_df.append(tmp, ignore_index = True) except Exception as e: continue return ticker_df
# still within the else clause new_tickers_df = ut.get_tickers_from_list(new_tickers, conn) # read in new tickers with their ids # Starting Price download from Yahoo Finance splits = ut.determine_splits(new_tickers, cf.BATCH_SIZE) new_tickers_list = [new_tickers_df.loc[i : i + cf.BATCH_SIZE - 1, : ] for i in range(0, len(new_tickers_df), cf.BATCH_SIZE)] new_excepts = [] count = 1 for batch in new_tickers_list: print("|---------------| Split {} of {} |---------------|".format(count, splits)) tmp = ut.write_historical_prices_yf(batch, conn, cursor, None, yesterday) new_excepts.append(tmp) count += 1 new_excepts = ut.flatten_exceptions(new_excepts) new_alpaca = pd.DataFrame() # Starting Price download from Alpaca for ticker in new_excepts: new_alpaca = new_alpaca.append(new_tickers_df[new_tickers_df['ticker'] == ticker]) ut.write_historical_prices_alpaca(new_alpaca, api, conn, cursor, None, yesterday)
One of my newly added tickers was YUMY, the VanEck Future of Food ETF. Querying the SMD shows that its price history, starting from its inception on December 1st, has been correctly downloaded.
SELECT ins.ticker, p.*
FROM instrument AS ins
INNER JOIN price AS p
ON ins.id = p.ticker_id
WHERE ins.ticker = 'YUMY';

5.2. Existing Instruments
So far, the update.py script neatly checks for new instruments and adds them and their complete price history to the database. But what about the already existing > 10,000 tickers? In this second part of the script, we’ll query the database for all tickers, excluding those that have just been added and therefore already have an up-to-date price history. Instead of assuming that the latest price_date in the database applies to all tickers as it has been the case in Robert Andrew Martin‘s update function, we’ll go the extra mile and determine the last_price for each ticker individually. We’ll then split these tickers into those that got their data from Yahoo Finance and those that got their data from Alpaca up until now to ensure consistency in the price histories. Finally, we’ll download price data to fill in the gaps between each ticker’s last price_date and yesterday’s (last past weekday’s) date.
In order to get the last price_date for each ticker, we need to do some more advanced SQL. My first and arguably naïve approach was to iterate over every ticker and join its instrument and price table entries such that I could determine the latest date for which pricing data was available for that ticker. Though this approach worked, it took around seven minutes to get a result from the function for the whole list of existing tickers!
# Don't do this def get_update_info_from_list(tickers, conn): ticker_df = pd.DataFrame() for ticker in tickers: try: sql = """ SELECT ins.ticker, ins.id, p.vendor_id, p.price_date FROM instrument AS ins INNER JOIN price AS p ON ins.id = p.ticker_id WHERE ins.ticker = '{}' and p.price_date = (SELECT MAX(price_date) FROM price WHERE ticker_id = ins.id);""".format(ticker) tmp = pd.read_sql(sql, conn) ticker_df = ticker_df.append(tmp, ignore_index = True) except Exception as e: continue return ticker_df
In hindsight, it is no wonder that this took so long. Instead of joining the instrument and price tables once, it does so more than 10,000 times – once for each ticker. That can’t be efficient!
Thus, my second approach used a nested SQL statement to first join the instrument and price tables on the ticker ids and then select the maximum of the price_date, grouped by ticker. This approach was not only written more elegantly, but also only took around a third of the time. Waiting an additional two minutes in exchange for detailed last price_date information for each ticker in the database is well worth in my opinion.
# Do this instead def get_update_info_from_list(conn, cursor): """ Gets latest price_date for every ticker in the database and returns it together with some other information :param conn: MySQL database connection :param cursor: MySQL database cursor for query execution :return: dataframe of tickers with their corresponding ids, vendor_ids and last price_dates """ cursor.execute("SET sql_mode = (SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));") # to use group by with an aggregated column sql = """ SELECT j.ticker, j.id, j.vendor_id, MAX(j.price_date) last_date FROM (SELECT ins.ticker, ins.id, p.vendor_id, p.price_date FROM instrument AS ins INNER JOIN price AS p ON ins.id = p.ticker_id) AS j GROUP BY j.id;""" return pd.read_sql(sql, conn)
You could imagine the returned dataframe to look something like this:
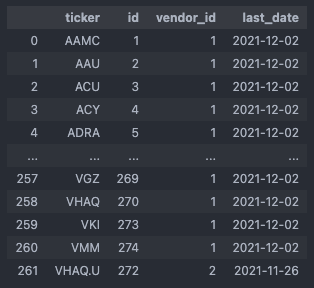
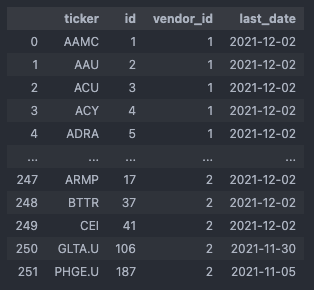
Before we pass this dataframe to the price update functions, we’ll just quickly remove those entries that belong to the newly added tickers whose price history is already up-to-date by definition, and those entries whose last price_date (= last_date) is equal to yesterday (note, that we need an additional yesterday_dt variable in datetime format, since we cannot compare last_date with a string). This assures that if we have to run the script again, e.g. due to some error on the API server side, the script will skip over those tickers that have just been updated and naturally do not have any new price data posted yet.
yesterday_dt = ut.get_yesterday() tickers_df = ut.get_update_info_from_list(conn, cursor) tickers_df = tickers_df[~tickers_df['ticker'].isin(new_tickers)] # filter out newly added tickers that are already up to date tickers_df = tickers_df[tickers_df['last_date'] != yesterday_dt] # filter out those tickers whose last_price date is equal to yesterday's date
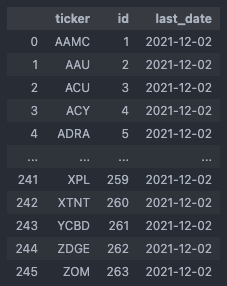
In the next step, we split the clean tickers_df dataframe into a yahoo_tickers_df (cast tickers to Yahoo Finance format again) and an alpaca_tickers_df, as well as get the corresponding vendor_ids from the database:
if tickers_df.empty: continue # prices are already up to date else: yahoo_tickers_df = tickers_df[tickers_df['vendor_id'] == ut.get_vendor_id('Yahoo Finance', conn)] yahoo_tickers_df.drop('vendor_id', axis = 1, inplace = True) # Casting tickers to yf format tmp = ut.cast_to_yf(yahoo_tickers_df['ticker'].tolist()) yahoo_tickers_df.drop('ticker', axis = 1, inplace = True) yahoo_tickers_df.insert(0, 'ticker', tmp) alpaca_tickers_df = tickers_df[tickers_df['vendor_id'] == ut.get_vendor_id('Alpaca', conn)] alpaca_tickers_df.drop('vendor_id', axis = 1, inplace = True) yf = ut.get_vendor_id('Yahoo Finance', conn) alp = ut.get_vendor_id('Alpaca', conn)
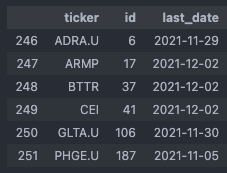
The price update functions for the Yahoo Finance tickers and the Alpaca tickers are actually very similar in structure. For each ticker of the corresponding dataframes, we’ll first determine the next_date, i.e. the date after its last_date as a starting point for the price download.
Due to Alpaca’s weirdly specific requirements for start and end dates, we have to add a timestamp to the next_date and end_date strings in the update_historical_prices_alpaca() function. For the update_historical_prices_yahoo() function, we have to manually drop the first row of the resulting dataframe because, for some reason and despite correctly specifying the next_date, Yahoo still returns data starting from the last_date.
After that’s done, we simply iterate over the rows of the returned dataframes and write the vendor_id, ticker_id and the downloaded price data directly into the database.
def update_historical_prices_yf(tickers_df, vendor, conn, cursor, end_date): """ Retrieves historical prices in a given timeframe for a set of tickers from Yahoo Finance and writes them directly to the database :param tickers_df: dataframe of tickers for which prices should be written :param vendor: vendor id :param conn: MySQL database connection :param cursor: MySQL database cursor for query execution :param end_date: latest price date """ for ticker in tqdm(tickers_df.itertuples()): try: next_date = str(ticker.last_date + datetime.timedelta(days = 1)) tmp = pdr.get_data_yahoo(ticker.ticker, start = next_date, end = end_date, progress = False) tmp = tmp.iloc[1:, :] # drop row for last price_date for row in tmp.itertuples(): values = [vendor, ticker.id] + list(row) sql = "INSERT INTO price (vendor_id, ticker_id, price_date, open_price, high_price, low_price, close_price, adj_close_price, volume) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(sql, tuple(values)) except Exception as e: print("Failed to update {}.".format(ticker.ticker)) continue conn.commit() print("|---------------| Data successfully written to database. |---------------|") return def update_historical_prices_alpaca(tickers_df, vendor, api, conn, cursor, end_date): """ Retrieves historical prices in a given timeframe for a set of tickers from Alpaca and writes them directly to the database :param tickers_df: dataframe of tickers for which prices should be written :param vendor: vendor id :param api: Alpaca api object :param conn: MySQL database connection :param cursor: MySQL database cursor for query execution :param end_date: latest price date """ for ticker in tqdm(tickers_df.itertuples()): try: next_date = str(ticker.last_date + datetime.timedelta(days = 1)) + 'T00:00:00-05:00' # adhering to the strict alpaca date format end_date = end_date + 'T00:00:00-05:00' # adhering to the strict alpaca date format tmp = api.get_barset(ticker.ticker, 'day', limit = 1000, start = next_date, end = end_date).df for row in tmp.itertuples(): values = [vendor, ticker.id] + list(row) sql = "INSERT INTO price (vendor_id, ticker_id, price_date, open_price, high_price, low_price, close_price, volume) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(sql, tuple(values)) except Exception as e: print('Failed to update {}.'.format(ticker.ticker)) continue conn.commit() print("|---------------| Data successfully written to database. |---------------|") return
Back in the update.py file, we call these two new functions, batch-wise for Yahoo tickers since those make up by far the largest portion of tickers in the SMD, and normally for Alpaca tickers.
# still within the else clause # Starting Price download from Yahoo Finance splits = ut.determine_splits(yahoo_tickers_df['ticker'].to_list(), cf.BATCH_SIZE) yahoo_tickers_list = [yahoo_tickers_df.loc[i : i + cf.BATCH_SIZE - 1, : ] for i in range(0, len(yahoo_tickers_df), cf.BATCH_SIZE)] count = 1 for batch in yahoo_tickers_list: print("|---------------| Split {} of {} |---------------|".format(count, splits)) ut.update_historical_prices_yf(batch, yf, conn, cursor, yesterday) count += 1 # Starting Price download from Alpaca ut.update_historical_prices_alpaca(alpaca_tickers_df, alp, api, conn, cursor, yesterday)
5.3. Close Connection to SMD
At the end of the script, we’ll first close the connection to the cursor, and then to the database itself:
cursor.close() conn.close()
5.4. Letting the Script run
Now it is time to run the script (make sure that your mysql server is running, mysql.server start), see if everything is working well and our SMD gets updated as expected.
For me, updating the whole database six days after its initial population took ca. 40 minutes, with 42 new instruments and 55,554 new rows of price data added. Depending on your internet connection, the amount of tickers in the database and the current load on the API servers, the updating time can vary significantly. For this run, I got between three and five tickers updated per second, whereas on a different day, I only got a throughput of one ticker per second.
Personally, I added some time.sleep() and print() statements throughout my update.py script for better readability and logging later on, making it look like this:
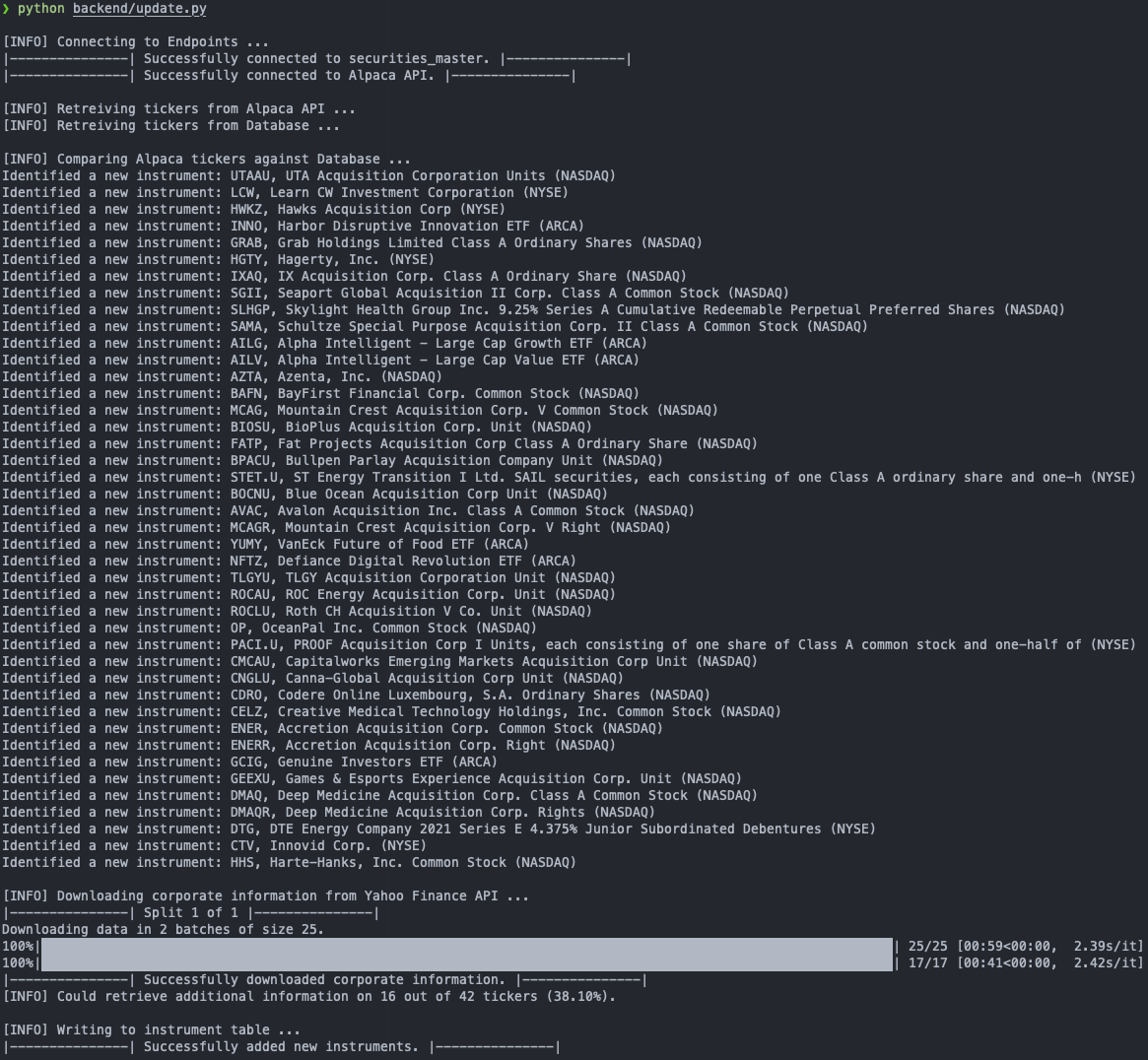
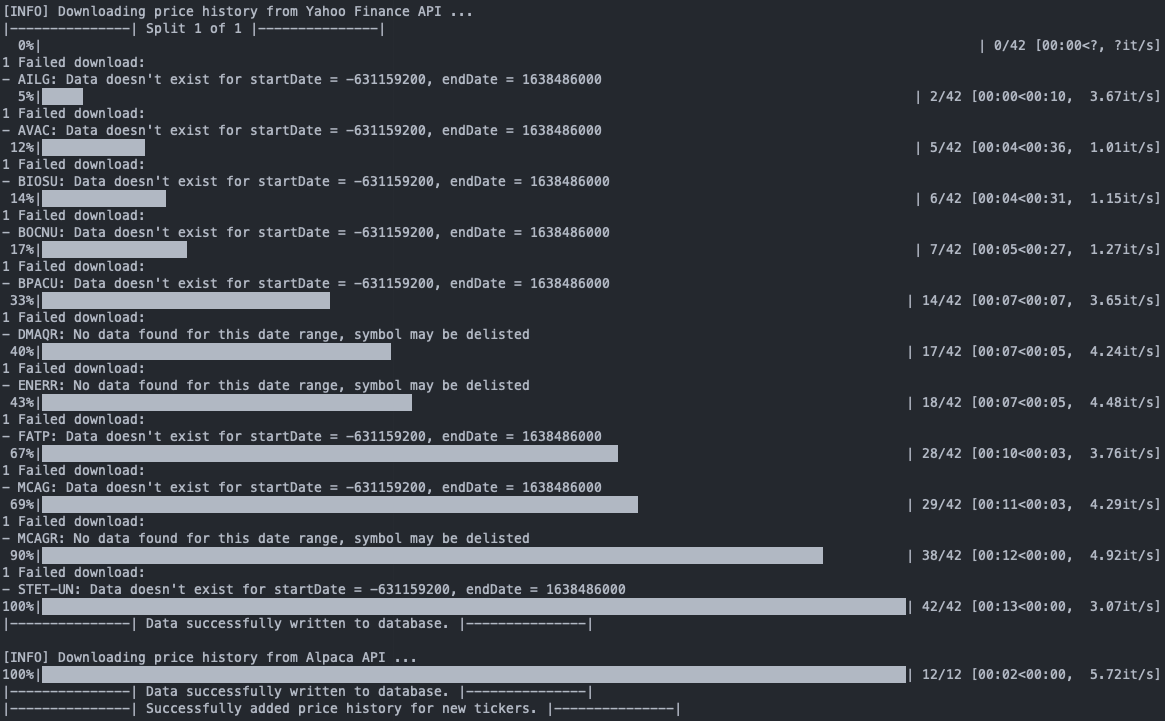
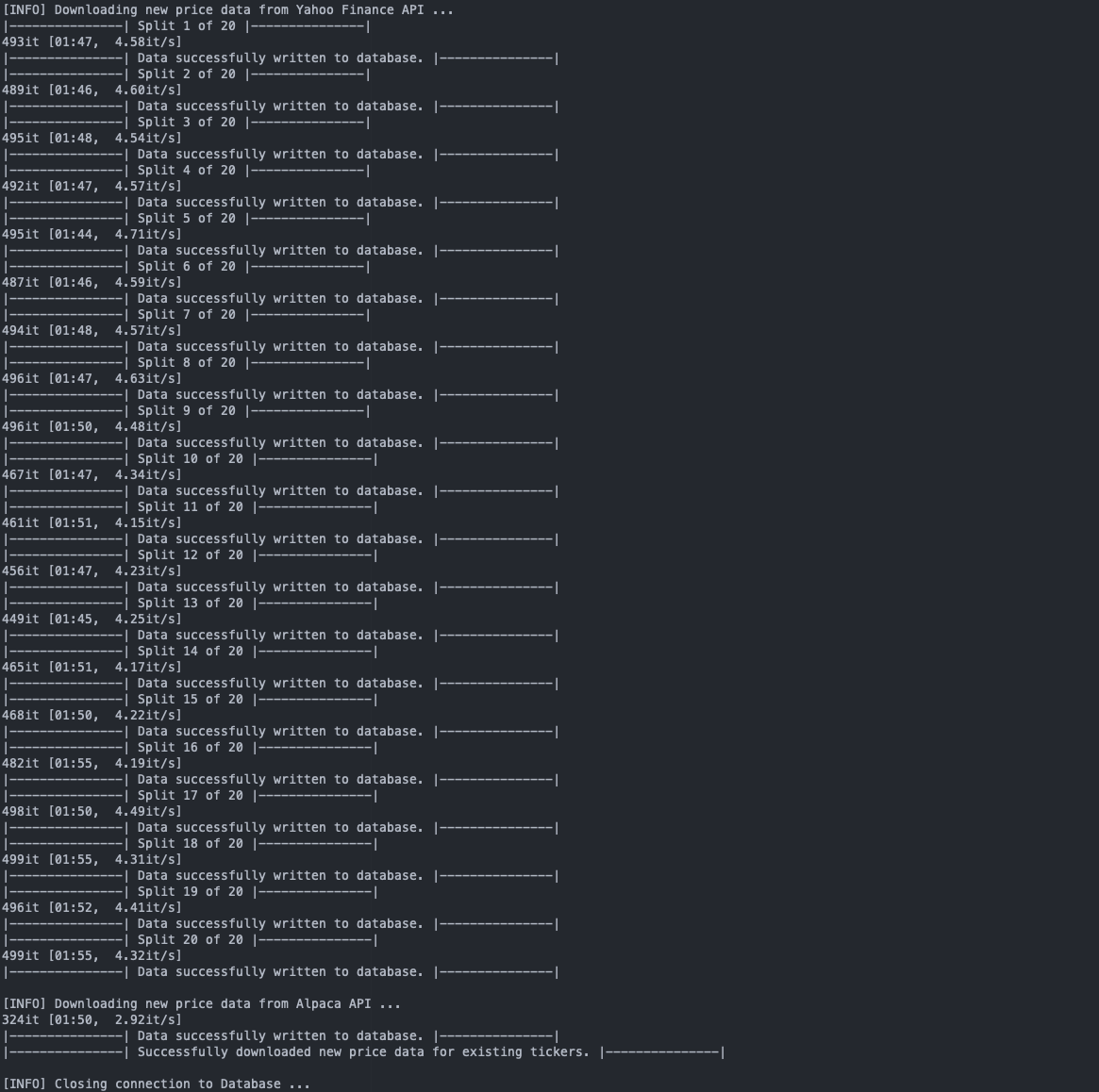
The script ran through without any problems, if you happen to get some JSONDecodeErrors, manually stop the script and restart it. Don’t worry, since progress is written to the database throughout the script and not just at the very end, your next run will skip over those entries and continue from where you’ve left off before.
Let’s take a look at Apple’s entries in the database to see, whether it updated correctly:
SELECT ins.ticker, p.* FROM instrument AS ins INNER JOIN price AS p ON ins.id = p.ticker_id WHERE ins.ticker = 'AAPL';
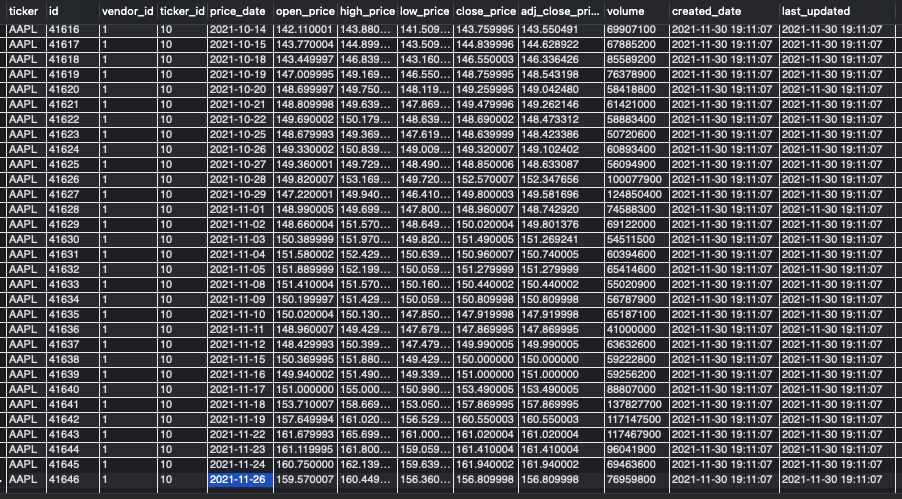
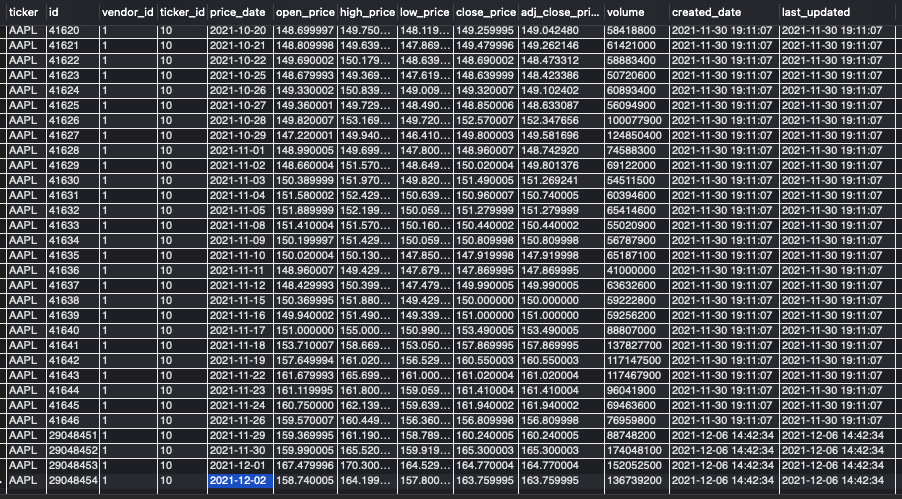
It is completely up to you in which intervals you’re going to run the update.py script. Getting one or 14 new data points per ticker does not really affect the runtime at all, so if you don’t need the latest price data as soon as it gets published, you might want to run the script weekly instead of daily. Personally, I’ll probably run the script bi-weekly on Sundays, at least as long as the SMD is still a local instance on my Mac and not on a server.
6. Interacting with the SMD
Now that our SMD is finally complete, let’s explore it a bit and learn how to interact with it. I am planning on building a full frontend to interact with the database in the future, but for now, let’s look at some core ways to work with our data. Note that your mysql server must be running (mysql.server start) to establish a connection with the database!
First, we need to import the config.py and utils.py files, as well as some additional libraries:
import config as cf import utils as ut import pandas as pd import numpy as np
Then, connect to the SMD as usual:
# Connect to DB conn = ut.connect_db()
To simplify interacting with our SMD, let’s write some functions that retrieve either only closing prices or the whole OHLCV data for a given ticker and add them to the utils.py file. Depending on which vendor the ticker of interest got its data from, the functions either return the adj_close_price (Yahoo) or the close_price (Alpaca).
def get_ohlcv_df(ticker, conn): """ Query the database for OHLCV data of a specified ticker :param ticker: ticker for which OHLCV data should be returned :param conn: MySQL database connection :return: dataframe with OHLCV data """ price = 'adj_close_price' # default: Yahoo Finance vendor = get_vendor_id_ticker(ticker, conn) if vendor == 2: price = 'close_price' # Alpaca sql = """ SELECT p.price_date, p.open_price, p.high_price, p.low_price, p.{}, p.volume FROM instrument AS ins INNER JOIN price AS p ON p.ticker_id = ins.id WHERE ins.ticker = '{}' ORDER BY p.price_date ASC;""".format(price, ticker) tmp = pd.read_sql(sql, conn, index_col = 'price_date') if tmp.empty: print('No data for {} in database.'.format(ticker)) sys.exit(1) return tmp def get_price_df(ticker, conn): """ Query the database for (adj) closing prices of a specified ticker :param ticker: ticker for which prices should be returned :param conn: MySQL database connection :return: dataframe with closing prices """ price = 'adj_close_price' # default: Yahoo Finance vendor = get_vendor_id_ticker(ticker, conn) if vendor == 2: price = 'close_price' # Alpaca sql = """ SELECT p.price_date, p.{} FROM instrument AS ins INNER JOIN price AS p ON p.ticker_id = ins.id WHERE ins.ticker = '{}' ORDER BY p.price_date ASC;""".format(price, ticker) tmp = pd.read_sql(sql, conn, index_col = 'price_date') if tmp.empty: print('No data for {} in database.'.format(ticker)) sys.exit(1) return tmp def get_vendor_id_ticker(ticker, conn): """ Given a MySQL database connection, query for the vendor id of a specified ticker :param ticker: ticker for which vendor id should be returned :conn: MySQL database connection :return: vendor id """ sql = """ SELECT DISTINCT (p.vendor_id) FROM instrument AS ins INNER JOIN price AS p ON p.ticker_id = ins.id WHERE ins.ticker = '{}';""".format(ticker) return pd.read_sql(sql, conn).astype(int).iloc[0]['vendor_id']
6.1. Simple Data Retrieval & Static Plotting (matplotlib)
Let’s start simple with getting closing prices for a specified ticker from our database and storing those in a dataframe:
ticker = 'AAPL' # Simple data call data = ut.get_price_df(ticker, conn) data.tail(10)
We can use the matplotlib library for some simple plotting:
import matplotlib.pyplot as plt plt.style.use('seaborn-darkgrid') plt.figure(figsize = (14, 5)) plt.plot(data, 'b') plt.grid(True) plt.title('{} Adj. Close Price'.format(ticker)) plt.xlabel('Trading Days') plt.ylabel('{} Adj. Close Price'.format(ticker)) plt.show()
Let’s take a look at the volatility of the ticker’s returns as well as the cumulative returns over the past year (252 trading days). To do so, we need to calculate the log returns and then calculate their standard deviation over a defined time window:
data['log_returns'] = np.log(data['adj_close_price'] / data['adj_close_price'].shift(1)) data['20_day_historical_volatility'] = 100 * data['log_returns'].rolling(window = 20).std() data.tail(10)
We can leverage matplotlib‘s subplots functionality to create a plot of the ticker’s price, log returns and volatility over the past year:
fig, axs = plt.subplots(3, sharex = True, figsize = (20, 10)) fig.suptitle('{} Analysis'.format(ticker), fontsize = 'xx-large') axs[0].plot(data['adj_close_price'], 'r', label = 'Adj. Close Price') axs[0].legend(loc = 'best') axs[1].plot(data['log_returns'], 'g', label = 'Log Returns') axs[1].legend(loc = 'best') axs[2].plot(data['20_day_historical_volatility'], 'b', label = '20 day Historical Volatility') axs[2].legend(loc = 'best')
6.2. Detailed Data Retrieval & Interactive Plotting (cufflinks)
Similarly, we can get a more detailed view of a specified ticker by calling the get_ohlcv_df() function and storing its result in a dataframe. Going forward, we will only need the past year’s prices, so we can reassign the data variable to its tail of 252 trading days.
ticker = 'AAPL' # Sophisticated data call data = ut.get_ohlcv_df(ticker, conn) data = data.tail(252)
Matplotlib is not the only library we can use for creating some nice plots. Cufflinks, for instance, is a great alternative that combines the power of plotly and pandas to produce interactive charts from dataframes.
import cufflinks as cuff from IPython.display import display, HTML cuff.set_config_file(sharing = 'public', theme = 'pearl', offline = True) data['adj_close_price'].iplot(kind = 'line', title = '{} Line Chart'.format(ticker), xTitle = 'Trading Days', yTitle = 'Adj. Close Price') data.iplot(kind = 'candle', rangeslider = True, title = '{} Candles'.format(ticker), xTitle = 'Trading Days', yTitle = 'OHLC')
Cufflinks also offers the powerful QuantFigure class that generates a persistent graph object which can be enhanced with several technical indicators such as Bollinger Bands, Simple Moving Averages, RSI and MACD:
qf = cuff.QuantFig(data, title = '{} Quant Figure'.format(ticker), legend = 'top', name = 'data') qf.add_bollinger_bands(periods = 20, boll_std = 2) qf.add_volume() qf.iplot()
If you want to go all out and generate a very detailed report on a stock’s price and technical analysis, you can switch from inline plots to browser based plots as follows:
import plotly.io as pio pio.renderers.default = "browser" qf = cuff.QuantFig(data, title = '{} Technical Analysis'.format(ticker), legend = 'top', name = 'data') qf.add_bollinger_bands(periods = 20, boll_std = 2, colors = ['magenta', 'grey'], fill = True) qf.add_sma([50, 150, 200], width = 3, color = ['green', 'lightgreen', 'lightblue'], legendgroup = True) qf.add_rsi(periods = 20, color = 'java') qf.add_macd() qf.add_volume() qf.iplot()
6.3. Comparing Tickers & Indices
It is standard industry practice to closely monitor the performance of indices such as the S&P 500 or the Dow Jones Industrial Average (for Germany, the DAX is the most renowned index), and most often compare individual portfolio performance against ‘the market’. The exact calculation of these indices is not trivial and depends amongst others on the market capitalization of their constituents. Luckily, though, there exist ETFs that closely track and imitate such indices, e.g. the SPY (SPDR S&P 500 Trust ETF), the QQQ (Invesco QQQ Trust ETF) for the Nasdaq-100, or the GLD (SPDR Gold Trust ETF).
Even better, we already have pricing data for these ETFs in our database:
spy = ut.get_price_df('SPY', conn) qqq = ut.get_price_df('QQQ', conn) gld = ut.get_price_df('GLD', conn) import matplotlib.pyplot as plt plt.style.use('seaborn-darkgrid') fig, axs = plt.subplots(3, sharex = True, figsize = (20, 10)) fig.suptitle('Index Tracking ETFs', fontsize = 'xx-large') axs[0].plot(spy['adj_close_price'], 'r', label = 'SPY') axs[0].legend(loc = 'best') axs[1].plot(qqq['adj_close_price'], 'g', label = 'QQQ') axs[1].legend(loc = 'best') axs[2].plot(gld['adj_close_price'], 'b', label = 'GLD') axs[2].legend(loc = 'best')
6.3.1. Index Constituents
Having the SPY in the SMD is very valuable and will serve us well later when we’re actually writing trading strategies and comparing their performance to that of the S&P 500. But wouldn’t it also be nice to get a list of all the 500 (actually 505) companies within the S&P 500 and cherry pick a few of them for some basic statistical comparison?
Let’s write some functions to scrape the Wikipedia page of the S&P 500 constituents and to get some information on these tickers from our SMD:
def get_SP500_constituents(): """ Scrapes the Wikipedia article on S&P500 constituents and returns a list of their tickers :return: list of S&P500 tickers """ url = 'https://en.wikipedia.org/wiki/List_of_S%26P_500_companies' page = requests.get(url) # handles the contents of the website doc = lh.fromstring(page.content) # stores website contents # data is stored in a table <tr>..</tr> tr_elements = doc.xpath('//tr') cols = [] # for each row, store each first element (header) and an empty list for t in tr_elements[0]: name = t.text_content() cols.append((name, [])) # actual data is stored on the second row onwards for j in range(1, len(tr_elements)): T = tr_elements[j] # T is j'th row # If row is not of size 9 (hard-coded), the //tr data is not from our table if len(T) != 9: break i = 0 # column index # iterate through each row element for t in T.iterchildren(): data = t.text_content() cols[i][1].append(data) # append data to empty list of i'th column i += 1 # next column col_names = {title:column for (title, column) in cols} df = pd.DataFrame(col_names) tickers = df['Symbol\n'].str.replace('\n', '').to_list() return tickers
This function closely followed Syed Sadat Nazrul’s article on how to scrape a website’s table, so best head over there for a detailed explanation. Basically though, we iterate over each row of the table and store its first element (i.e. the header) in a list of column names. Then, we iterate over the remaining rows and add their contents to a dataframe. Since I’m only interested in the tickers, I’m just returning the Symbol column, casted to a list.
def get_ticker_info_from_list(ticker_list, conn): """ Returns a dataframe with instrument information for a given list of tickers :param index: list of tickers :param conn: MySQL database connection :return: dataframe of instrument information """ ticker_df = pd.DataFrame() for i in range(0, len(ticker_list)): try: sql = """ SELECT ex.acronym, ins.ticker, ins.name, ins.sector, ins.industry, ins.country, ins.website FROM exchange AS ex INNER JOIN instrument AS ins ON ex.id = ins.exchange_id WHERE ins.ticker = '{}';""".format(ticker_list[i]) tmp = pd.read_sql(sql, conn) ticker_df = ticker_df.append(tmp, ignore_index = True) except Exception as e: continue return ticker_df
By calling these two new functions, we get a dataframe with some key information on every ticker included in the S&P 500:
sp500 = ut.get_SP500_constituents() # get list of S&P 500 tickers sp500_df = ut.get_ticker_info_from_list(sp500, conn)
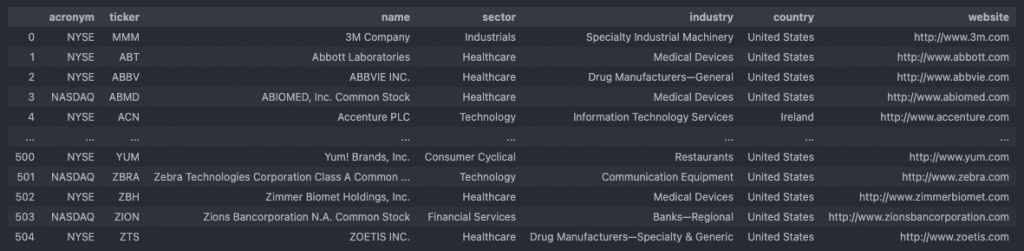
6.3.2. Comparing Tickers
Now that we’re able to query our database for (theoretically any) index constituents, let’s write yet another function to load in closing prices for a subset of S&P 500 tickers:
def compare_tickers(tickers, conn): """ Takes in a list of tickers, queries the database for their closing prices and returns a dataframe with all values :param tickers: list of tickers for which closing prices should be returned :param conn: MySQL database connection :return: dataframe with closing prices for the ticker list """ tickers_df = pd.DataFrame() for ticker in tickers: tmp = get_price_df(ticker, conn) if tmp.columns[0] == 'adj_close_price': # ticker is a Yahoo ticker tmp = tmp.rename(columns = {'adj_close_price' : ticker}) else: # ticker is an Alpaca ticker tmp = tmp.rename(columns = {'close_price' : ticker}) tickers_df = pd.concat([tickers_df, tmp], axis = 1) return tickers_df.sort_values(by = ['price_date'], ascending = True)
tickers = ['AAPL', 'AMZN', 'FB', 'F', 'GOOG', 'JNJ', 'SPY'] tickers_df = ut.compare_tickers(tickers, conn) tickers_df = tickers_df.tail(252)
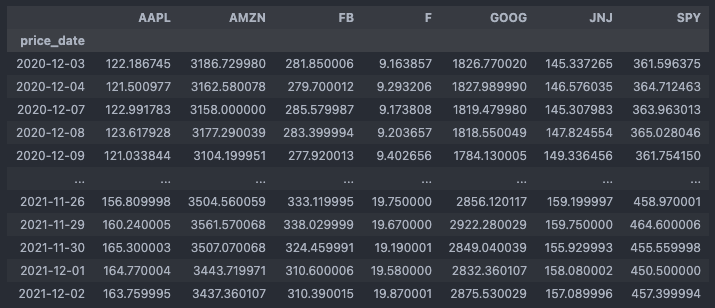
We don’t want to compare the individual price histories of these tickers but rather their returns. So, with a little help of pandas‘ df.pct_change() function, we can easily calculate the returns of our ticker selection:
returns_df = tickers_df.pct_change()

To compare the correlation of returns for these tickers, we can make use of the seaborn library and its jointplot() and pairplot() functions:
import matplotlib.pyplot as plt import seaborn as sns sns.set_style('whitegrid') sns.jointplot('AAPL', 'GOOG', returns_df, kind = 'scatter') sns.pairplot(returns_df.dropna())
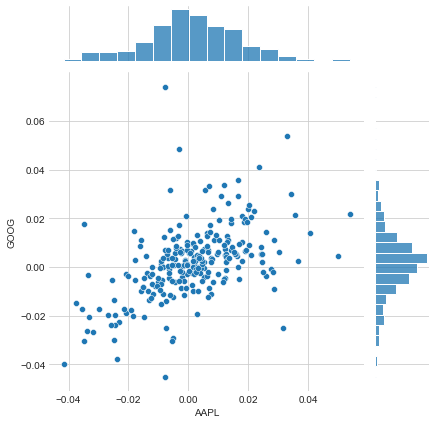
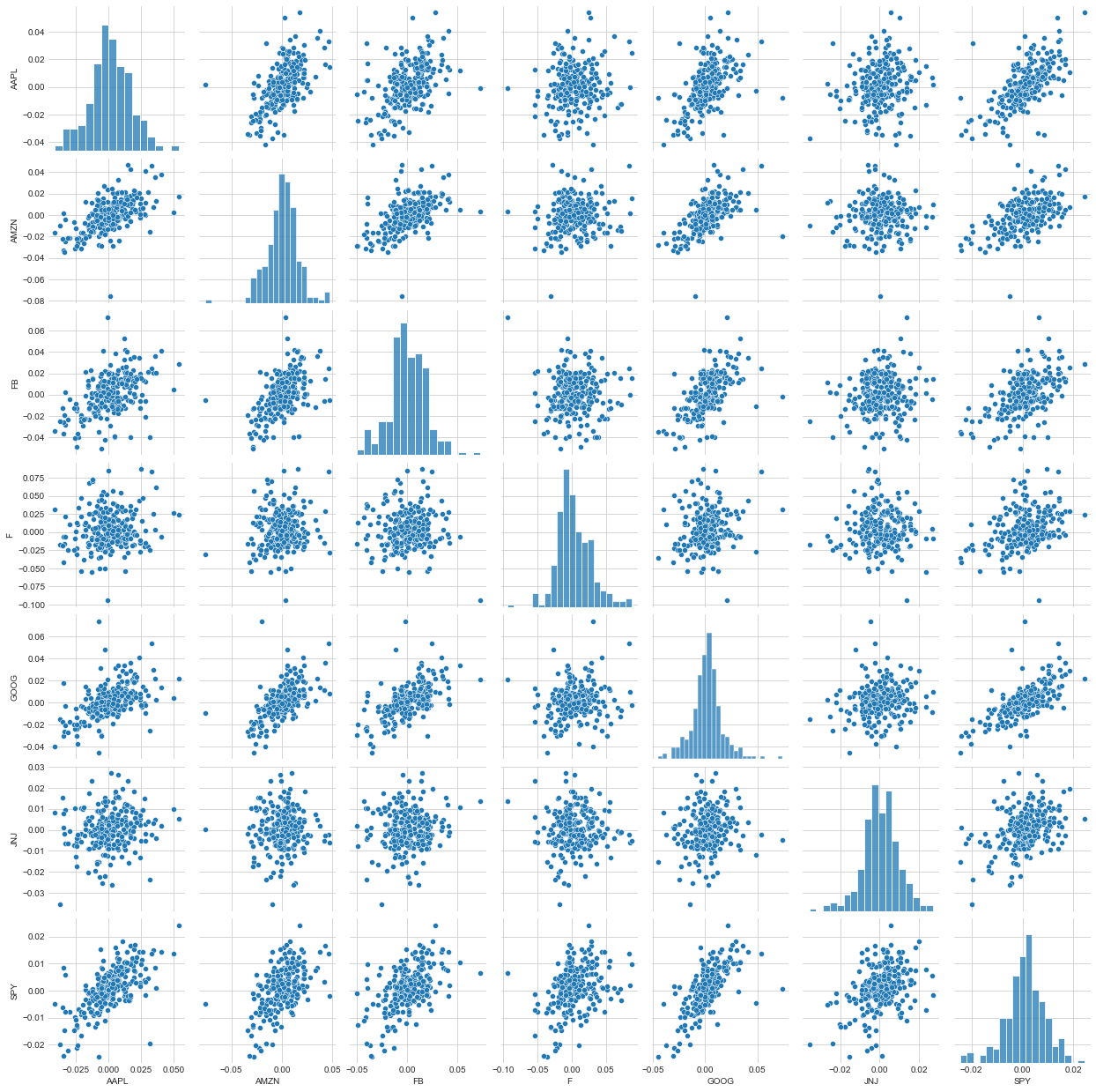
A different representation of ticker correlations can be achieved via a heatmap:
corr_df = returns_df.corr(method = 'pearson') mask = np.zeros_like(corr_df) mask[np.triu_indices_from(mask)] = True plt.figure(figsize = (14, 10)) plt.title('Correlation Heatmap', fontsize = 'xx-large') sns.heatmap(corr_df, cmap = 'RdYlGn', vmax = 1.0, vmin = -1.0 , mask = mask, linewidths = 8.0) plt.yticks(rotation = 0) plt.xticks(rotation = 90) plt.show()
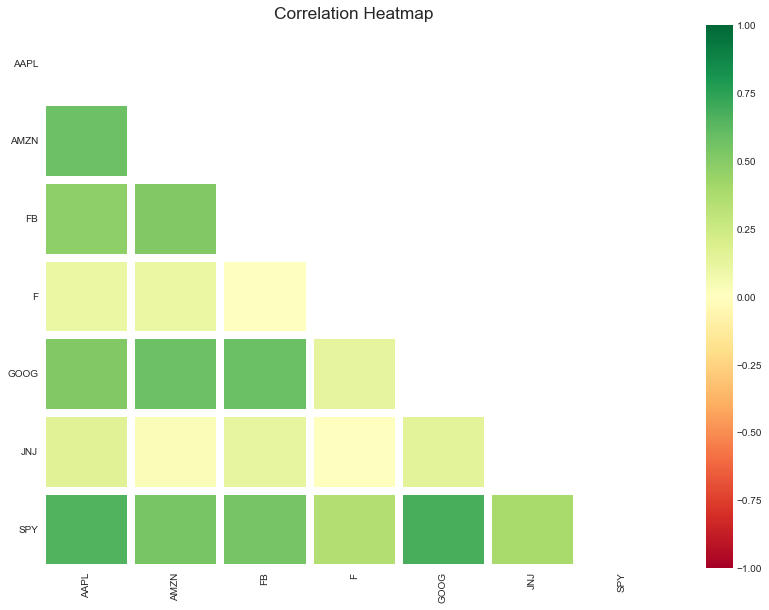
From this representation we can easily see that AAPL and GOOG are most closely correlated to the SPY and that the typical tech stocks are intercorrelated aswell (no surprise there). Ford and Johnson & Johnson show no correlation at all to the other tickers, which makes sense given that they are in completely different industries.
Lastly, we can calculate the normalized returns of our ticker selection for the time frame of one year:
returns_norm_df = tickers_df / tickers_df.iloc[0 , :]
import cufflinks as cuff from IPython.display import display, HTML cuff.set_config_file(sharing = 'public', theme = 'pearl', offline = True) returns_norm_df.iplot(title = 'Normalized Returns of Ticker Selection', xTitle = 'Dates', yTitle = 'Normalized Returns')
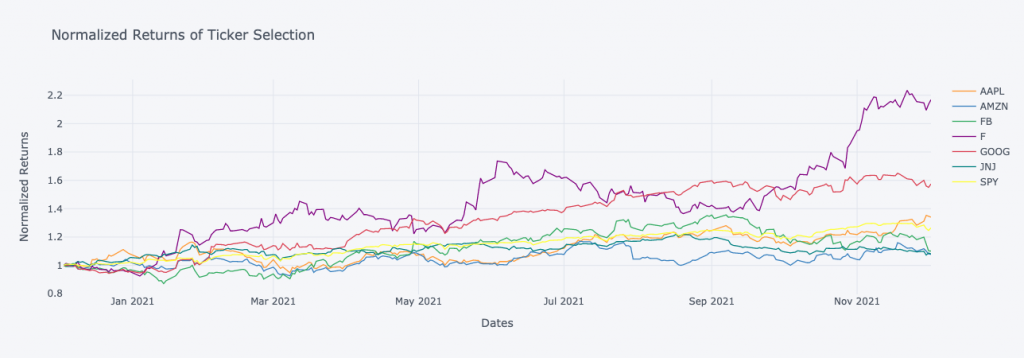
This chart nicely displays how each of the stocks from our selection of S&P 500 companies performed over the past year. Since we normalized the returns before, we can compare them easily between individual stocks. Surprisingly, Ford actually outperformed all the tech stocks and more than doubled in value while Johnson & Johnson barely made any advances at all. Note, how the Apple (orange) and SPY (yellow) chart lines are nearly overlapping, confirming the high positive correlation assumption we made earlier when charting the heatmap.
With this chapter I tried to give you a broad overview on what to do with all your newly collected data and, most importantly, how to do it. There are infinite possibilities to interact with the SMD and in one of my future posts, I will surely go into much more detail. But for now, I’m confident that the information above suffices for some first manual analysis and charting.
7. Open Issues
This article served as a beginner-friendly and comprehensive guide to building up a MySQL database from scratch for storing historical price data for a large number of financial instruments. I went in great detail over the database schema, table design and initial population via the Alpaca and Yahoo Finance APIs. Additionally, I went over writing a script for updating both, instruments and prices, to keep the database always up-to-date. Lastly, I gave some inspiration on how to interact with the database – from simple price retrieval and basic plotting to more sophisticated approaches of querying for OHLCV data, creating interactive and dynamic plots from it and working with lists of index constituents.
If you’ve followed my setup, you now have your personal Securities Master Database and know how to interact with it. Having a stable and reliable source of high quality data is already pretty nice, but in the coming blog posts, we will explore even further how to leverage it for backtesting of trading strategies.
Sometime in the future, I’m planning on upgrading my SMD and sharing my experiences and results in yet another post. Some ideas comprise:
- hosting the SMD on a Raspberry Pi instead of locally on my Mac
- setting up user profiles for people other than me
- building a frontend to explore the contents of the database outside of MySQL Workbench
- letting the SMD update itself regularly via cronjobs (weekly or even daily)
- letting the SMD clean itself monthly via cronjobs (check for delisted tickers and delete instrument and price data, check for name changes, e.g. Facebook > Meta and update the instrument table, delete SPACs from the database, etc.)
- adding new tables for fundamental data, trading strategies, watchlists, etc.
- …
8. References
- QuantStart Article
- Robert Andrew Martin’s Blog
- Hacking the Markets (Part Time Larry’s YouTube Series)